28 The Law of Large Numbers and Interpreting Probability
$$
$$
In Chapter 1, we discussed the frequentist interpretation of probability, which says that the probability \(P(A)\) corresponds to the long-run frequency of the event \(A\) in repeated trials. In Chapter 9, we discussed how the expected value \(\text{E}\!\left[ X \right]\) corresponds to the long-run average of repeated realizations of the random variable \(X\). In this chapter, we will develop a mathematical framework in which these assertions can be proven. The resulting theorem is called the Law of Large Numbers.
Here is the mathematical framework: repeated realizations of a random variable \(X\) can be modeled as independent and identically distributed (i.i.d.) random variables \(X_1, X_2, X_3, \dots\), all with the same distribution as \(X\).
The average of the first \(n\) observations is called the sample mean, which we write as follows: \[ \bar{X}_n \overset{\text{def}}{=}\frac{X_1 + X_2 + \dots + X_n}{n}. \] We will show that, under the assumption that \(\mu \overset{\text{def}}{=}\text{E}\!\left[ X_i \right]\) and \(\text{Var}\!\left[ X_i \right]\) exist and are finite, \[ \bar{X}_n \text{ ``$\to$'' } \mu \qquad \text{as $n\to\infty$}. \tag{28.1}\] We put quotes around the convergence arrow because this is different from the limits you encountered in calculus; the left-hand side is a random variable, while the right-hand side is a constant. We will also need to define what is meant by “convergence” in this context.
An informal way to justify Equation 28.1 is to calculate the expectation and variance of \(\bar{X}_n\).
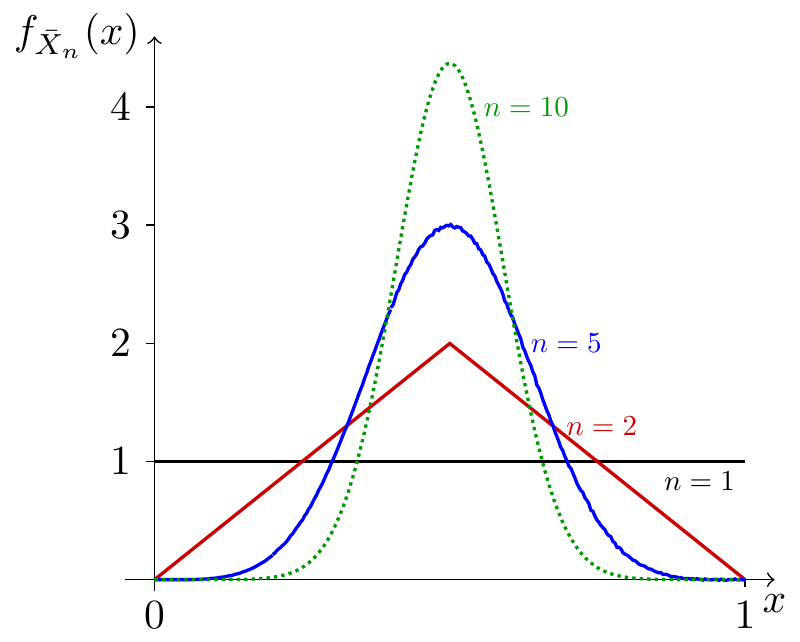
As \(n\) increases, the expected value remains constant at \(\mu\), while the variance decreases to zero. This means that the probability will become more and more “concentrated” near \(\mu\) as \(n\) increases. Figure 28.1 shows what happens for i.i.d. \(\textrm{Uniform}(a= 0, b= 1)\) random variables \(X_1, X_2, X_3, \dots\).
We can also explore this phenomenon by simulation. The simulation below simulates \(\bar{X}_n\) for i.i.d. \(\textrm{Exponential}(\lambda=1)\) random variables.
- Try increasing \(n\), and observe how \(\bar{X}_n\) “concentrates” around the expected value \(\mu = 1\) as \(n\) increases.
- Try changing the distribution (Poisson? normal?), and verifying that \(\bar{X}_n\) behaves in the same way.
28.1 Convergence in Probability
The simulation above illustrates how the random variable \(\bar{X}_n\) “concentrates” around \(\mu\) as \(n\) increases. To make this precise, we need the following definition.
That is, no matter how small \(\varepsilon\) is, \(Y_n\) will eventually be within \(\varepsilon\) of \(c\) with probability close to \(1\).
The Law of Large Numbers, which we prove in Theorem 28.2, is simply the statement that \[ \bar{X}_n \overset{p}{\to} \mu. \]
Clearly, convergence in probability requires that we be able to provide bounds on how far random variables can deviate from their expected value. In other words, these bounds indicate how much random variables “concentrate” around their expected value. For this reason, they are called concentration inequalities.
28.2 Concentration Inequalties
The next result, Chebyshev’s inequality, is a corollary of Markov’s inequality.
One consequence of Corollary 28.1 is that the probability that a random variable \(Y\) is within \(k\) standard deviations of of the mean is at least \(1 - \frac{1}{k^2}\). Some books use the name “Chebyshev’s inequality” for this special case.
Notice that Equation 28.5 tends to be a conservative lower bound. For example, if \(Y\) is normally distributed, then we know that \(P(|Y - \mu| > 2\sigma) \approx .95\), whereas Equation 28.5 only guarantees that \[ P(|Y - \mu| > 2\sigma) \geq 1 - \frac{1}{2^2} = .75. \] Why is this lower bound so far from the actual probability? Remember that Chebyshev’s inequality must hold for any distribution, not just the normal distribution.

Markov and Chebyshev were 19th century Russian mathematicians. In fact, Chebyshev is considered the “father of Russian mathematics.” Markov was Chebyshev’s student, and the result we know today as Markov’s inequality (Theorem 28.1) was known to Chebyshev—not surprisingly, since Markov’s inequality is needed to prove Chebyshev’s inequality. Markov popularized the inequality in his doctoral dissertation, which is why it has come to be named for him.

28.3 The Law of Large Numbers
The Law of Large Numbers is a direct consequence of Chebyshev’s inequality (Corollary 28.1), applied to the random variable \(\bar{X}_n\).
Bernoulli’s theorem, which provided a firm mathematical footing for the frequentist interpretation of probability, is a special case of the Law of Large Numbers.
We have come full circle. In Chapter 1, we asserted Equation 28.7 to be the interpretation of probability. Now, with the machinery that we have developed over the past 28 chapters, this interpretation is now a theorem!
28.4 Exercises
Exercise 28.1 Explain why the non-negativity is necessary in Markov’s inequality. In other words, come up with a random variable \(X\) and \(a > 0\) such that \[ P(X \geq a) > \frac{\text{E}\!\left[ X \right]}{a}. \]
Exercise 28.2 We want to estimate the proportion \(p\) of the Stanford population who is left-handed. We sample \(n\) people and find \(X\) people are left-handed. Show that \[ P\left( \left\lvert \frac{X}{n} - p \right\rvert > a \right) \leq \frac{1}{4na^2} \] for any \(a > 0\).
Exercise 28.3 Let \(X_1, \dots, X_n\) be i.i.d. \(\text{Normal}(\mu,\sigma^2)\). For what values of \(n\) are we at least \(99\%\) certain that \(\bar{X}\) is \(2\) standard deviations within the population mean \(\mu\)? How about \(99.9\%\) certain?
Exercise 28.4 Let \(X \sim \text{Uniform}(0, 8)\) and consider \(P(X \geq 6)\). Give the upper bounds of the probability via Markov’s inequality and Chebyshev’s inequality; compare the results with the actual probability.
Exercise 28.5
- Let \(X\) be a discrete random variable taking values \(1, 2, \dots\). If \(P(X = k)\) is non-increasing in \(k\), show that \[ P(X = k) \leq \frac{2 \text{E}\!\left[ X \right]}{k^2}. \]
- Let \(X \sim \text{Geometric}(p)\). Use the previous part to give an upper bound for \(\displaystyle \frac{k^2}{2^k}\) for all positive integers \(k\). What is the actual maximum?
Exercise 28.6
- Let \(X\) be a non-negative continuous random variable with a non-increasing density function \(f_X(x)\). Show that \[ f_X(x) \leq \frac{2 \text{E}\!\left[ X \right]}{x^2} \] for all \(x > 0\).
- Let \(X \sim \text{Exponential}(\lambda)\). Use the previous part to give an upper bound for \(\displaystyle \frac{\lambda^2}{e^\lambda}\) for all positive \(\lambda\). What is the actual maximum?