4 Properties of Probability Functions
$$
$$
In Chapter 3, we defined a probability function \(P\) rigorously by specifying the axioms that \(P\) must satisfy. In this chapter, we derive a few consequences of those axioms, which will enhance our toolset for computing probabilities.
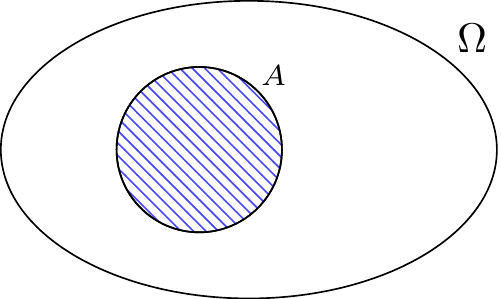
Throughout this chapter, we will illustrate sample spaces and events with diagrams like Figure 4.1.
In Figure 4.1, the area of the event \(A\), shaded in blue, represents the probability \(P(A)\). Since Kolmogorov’s second axiom (see Definition 3.1) requires \(P(\Omega) = 1\), we imagine that the area of the entire sample space is one. Therefore, \(P(A)\) can be thought of as the proportion of the sample space that \(A\) occupies.
4.1 Complement Rule
In many situations, the probability of an event is difficult to calculate directly, but the probability of its complement is straightforward. The complement rule relates the two probabilities.
Proposition 4.1 (Complement rule) For any event \(A\),
\[P(A^c) = 1 - P(A).\]
Proof
Intuitively, the statement is true because, as Figure 4.2 shows, the sum of the areas covered by \(A\) and \(A^c\) is equal to the area covered by the sample space \(\Omega\), which is \(1\).
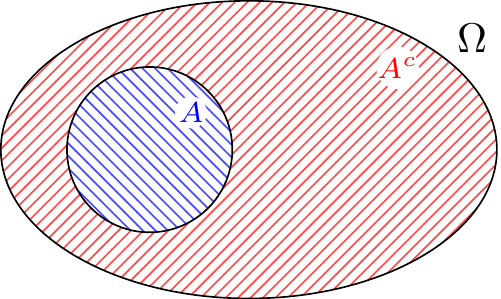
To prove this formally, note that \(A\) and \(A^c\) are disjoint, and their union is \(\Omega\).
Therefore, by Axiom 3 of Definition 3.1, \[ P(\Omega) = P(A \cup A^c) = P(A) + P(A^c), \] and by Axiom 2, \(P(\Omega) = 1\). The result now follows by moving \(P(A)\) to the other side.
We already used the complement rule implicitly when solving Cardano’s problem in Solution 2.1. The next example spells this out explicitly.
Kolmogorov’s axioms (Definition 3.1) do not directly guarantee that probabilities have to be between zero and one. However, this is an immediate consequence of the complement rule.
4.2 Subset Rule
If a set \(B\) is contained within another set \(A\) (see Figure 4.3), then we say that \(B\) is a subset of \(A\), which we write as \(B \subseteq A\). This means that whenever the event \(B\) happens, the event \(A\) also happens. The next result relates the probability of two events when one is a subset of another.
Proposition 4.3 (Subset rule) For any events \(A\) and \(B\) such that \(B \subseteq A\), \[P(B) \leq P(A).\]
Proof
Intuitively, when \(B\) is a subset of \(A\) it cannot cover a larger portion of the sample space than \(A\).
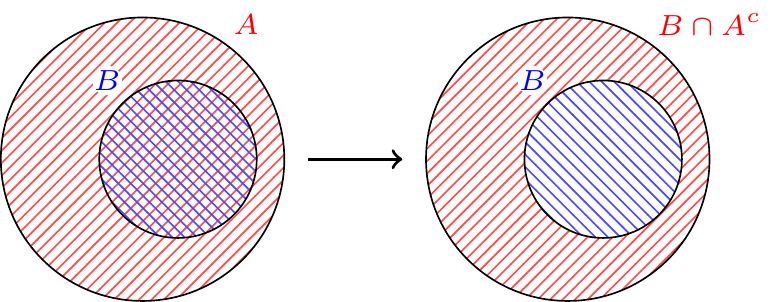
To prove this formally, we observe that if \(B \subseteq A\), we can write \(A\) as the disjoint union of \(B\) and \(A \cap B^c\).
Now, by Axiom 3 (see Definition 3.1), \[P(A) = P(B) + P(A \cap B^c). \] Since Axiom 1 (see Definition 3.1) guarantees that \(P(A \cap B^c) \geq 0\), it must be the case that \(P(A) \geq P(B)\).
Even though the subset rule seems obvious in the abstract, it is not always intuitive when applied to real-world problems, as the next example shows.
As another example, we can use Proposition 4.3 to establish that the probability of tossing the infinite sequence HHHHHHH... with a fair coin is zero.
4.3 Properties of Unions
4.3.1 Union of Two Events
If two events are mutually exclusive, then we can calculate the probability of their union by simply adding their probabilities (by Axiom 3 of Definition 3.1). What if they are not mutually exclusive? The next result provides a general way to calculate the probability of the union of two events.
Proposition 4.4 (Addition rule) For any events \(A\) and \(B\),
\[P(A \cup B) = P(A) + P(B) - P(A \cap B).\]
Proof
\(P(A \cup B)\) is the total area covered by the two circles in Figure 4.4. Intuitively, we see that adding together \(P(A)\) and \(P(B)\) double-counts the area in their intersection. Subtracting \(P(A\cap B)\) corrects for this overcounting. We formalize this argument below.
To make use of Axiom 3, we need to express \(A \cup B\) as a union of sets that are disjoint. As illustrated below, \(A \cup B\) can be written as the disjoint union of \(A\) and \(A^c \cap B\), the part of \(B\) that is not in \(A\).
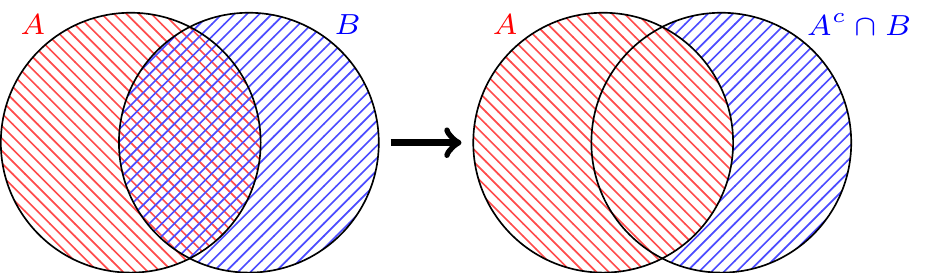
So by Axiom 3: \[P(A \cup B) = P(A \cup (A^c \cap B)) = P(A) + P(A^c \cap B).\]
To complete the proof, we need to show that \(P(A^c \cap B) = P(B) - P(A \cap B)\). But again, we can write \(B\) as the disjoint union of \(A \cap B\), the part of \(B\) that is in \(A\), and \(A^c \cap B\), the part of \(B\) that is not in \(A\):
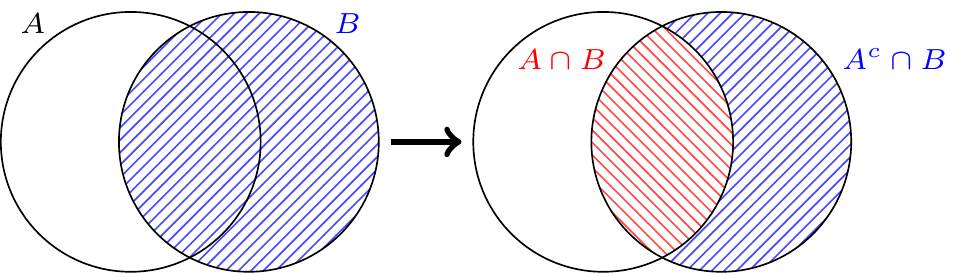
By Axiom 3, \(P(A \cap B) + P(A^c \cap B) = P(B)\). By moving \(P(A \cap B)\) to the other side, we obtain the desired result.
The addition rule describes a fundamental relationship between \(P(A)\), \(P(B)\), \(P(A \cap B)\), and \(P(A \cup B)\). If we know or can compute three of these, we can find the fourth.
4.3.2 The Union Bound
Because \(P(A \cap B) \geq 0\), the sum of the individual probabilities \[ P(A) + P(B) \] overestimates the probability of the union \[ P(A \cup B) = P(A) + P(B) - P(A \cap B). \] In other words, the sum of the individual probabilities is an upper bound for the probability of the union: \[ P(A \cup B) \leq P(A) + P(B). \]
This fact generalizes to the union of more than two events.
The union bound is useful for bounding probabilities of rare events.
Although the union bound can be useful for rare events, it can produce unhelpful answers.
The union bound also extends to countably infinite events \(A_1, A_2, \dots\).
4.3.3 Inclusion-Exclusion Principle
As we saw in Example 4.6, the union bound does not always yield helpful answers. Now, we discuss how to calculate the probability of a union exactly, although the method is not always easy to apply.
To build intuition for the general result, we first consider the union of three events. Conceptually we can think of the probability \(P(A \cup B \cup C)\) as the area of the region covered by the three circles in Figure 4.6.
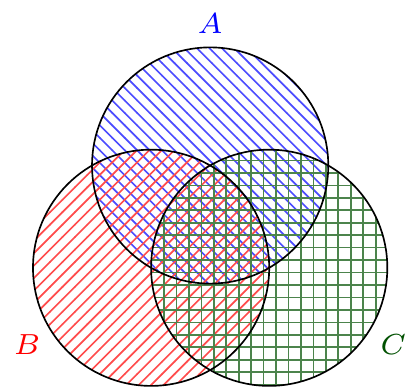
If we add together the areas of the circles \(A\), \(B\), and \(C\), this will double-count the area in the intersections \(A \cap B\), \(B \cap C\), and \(A \cap C\). We could try to adjust for this by subtracting off the probability of each intersection once:
\[P(A) + P(B) + P(C) - P(A \cap B) - P(B \cap C) - P(A \cap C). \]
However, now the area in the intersection \(A \cap B \cap C\) has been added in three times by \(P(A)\), \(P(B)\), and \(P(C)\) but also subtracted three times by \(P(A \cap B)\), \(P(B \cap C)\), and \(P(A \cap C)\). Therefore, we have to add it back in once, yielding the formula
\[P(A \cup B \cup C) = P(A) + P(B) + P(C) - P(A \cap B) - P(B \cap C) - P(A \cap C) + P(A \cap B \cap C). \]
The inclusion-exclusion principle generalizes this result to the union of \(n\) events.
Equation 4.6 is notationally dense, so we break it down:
\[ \textcolor{orange}{\underbrace{\sum_{i=1}^n P(A_i)}_{(1)}} - \textcolor{magenta}{\underbrace{\sum_{1 \leq i < j \leq n } P(A_i \cap A_j)}_{(2)}} + \textcolor{purple}{\underbrace{\sum_{1 \leq i < j < k \leq n} P(A_i \cap A_j \cap A_k)}_{(3)}} - \dots + (-1)^{n+1} \textcolor{brown}{\underbrace{P(A_1 \cap \dots \cap A_n)}_{(n)}}.\]
Since each of the terms \(\textcolor{orange}{(1)}, \textcolor{magenta}{(2)}, \textcolor{purple}{(3)}, \dots, \textcolor{brown}{(n)}\) is a sum, we can regard the expression as an alternating sum of sums. It is alternating in the sense that we start with the sum \(\textcolor{orange}{(1)}\), then subtract the sum \(\textcolor{magenta}{(2)}\), then add the sum \(\textcolor{purple}{(3)}\), and so on. The \(m\)th term is essentially a sum over the different ways one can choose \(m\) events from the \(n\) events in the union. As such, Proposition 2.3 tells us that the \(m\)th term is the sum of \({{n}\choose{m}}\) different probabilities; the last term \(\textcolor{brown}{(n)}\) is the sum of just \({{n}\choose{n}} = 1\) probability.
For example, if \(n=4\), then the second term \(\textcolor{magenta}{(2)}\) can be expanded as
\[ \begin{align*} \textcolor{magenta}{\sum_{1 \leq i < j \leq n } P(A_i \cap A_j)} &= \textcolor{magenta}{P(A_1 \cap A_2) + P(A_1 \cap A_3)+ P(A_1 \cap A_4)} \\ &\qquad \textcolor{magenta}{ + P(A_2 \cap A_3)+ P(A_2 \cap A_4)+ P(A_3 \cap A_4)}. \end{align*} \]
Now, we can use the inclusion-exclusion principle to calculate the exact probability that no one draws their own name in Secret Santa.
What happens to this probability as the number of friends \(n\) who participate in Secret Santa increases? On the one hand, the number of friends who could potentially draw their own name increases. On the other hand, the probability that each friend draws their own name decreases to zero. Which of these two effects predominates? Exercise 4.5 asks you to investigate.
Example 4.8 demonstrates the downsides of using inclusion-exclusion to calculate probabilities; it usually leads to an expression that is complex, even when a simple one exists. Usually, the probability of a union is more easily calculated using the complement rule (Proposition 4.1). We recommend trying the complement rule first and turning to inclusion-exclusion only as a last resort.
4.4 Exercises
Exercise 4.1 (Probabilities of intersections and unions) [*]
Let \(A\) and \(B\) be events. Prove that \[ P(A \cap B) \leq P(A \cup B). \] Under what situation would the two probabilities be equal?
Exercise 4.2 (Probability of exactly one event occurring) [*]
Let \(A\) and \(B\) be events. Prove that \[ P(\text{$A$ or $B$ occurs, but not both}) = P(A) + P(B) - 2 P(A \cap B). \]
Exercise 4.3 (Intersection of events with probability one) [**]
Let \(A_1, A_2, A_3, \dots\) be a countable collection of events such that \[ P(A_i) = 1. \]
Prove that \(P\Big(\bigcap_{i=1}^\infty A_i\Big) = 1\).
Exercise 4.4 (Bilingualism in India) [*]
According to the 2011 Census of India, \(57.1\%\) of the people in India can speak Hindi and \(10.6\%\) of them can speak English. If the percentage of people who speak both is between \(2\%\) and \(5\%\), what can we say about the percentage of people in India who speak at least one of Hindi or English?
Exercise 4.5 (Secret Santa with \(n\) friends) [**]
In Example 4.7, we calculated the probability that no one draws their own name when \(n=4\) friends participate in a Secret Santa gift exchange. What happens to this probability as \(n \to \infty\)? Be sure to simplify expressions fully. The answer in the end should be clean.
Exercise 4.6 (At least one face card) [*]
You are dealt a five-card poker hand from a shuffled deck of playing cards. What is the probability that there is at least one face card (J, Q, or K) in the five-card hand?
- Calculate this using the complement rule.
- Calculate this using inclusion-exclusion.
Exercise 4.7 (Probability of infinitely many heads) [***]
Let \(\Omega\) be the sample space of all infinite sequences of coin tosses, with the probability function \(P\) as defined in Example 3.11.
Show that \(P(\text{infinitely many heads}) = 1\).
Hint: Write the event in terms of unions and intersections of \(A_1, A_2, \dots\) (as defined in Example 3.11), and consider its complement.