37 Functions of Means
$$
$$
In Example 30.2, we saw that in order to estimate the rate parameter \(\lambda\) from i.i.d. exponential observations, the MLE is \[ \hat\lambda = \frac{n}{\sum_{i=1}^n X_i} = \frac{1}{\bar X}. \]
In other words, \(\hat\lambda\) is of the form \(g(\bar X)\), where \(g\) is a twice-differentiable function. We know that \(\bar X\) is unbiased and consistent for the mean parameter \(\mu = \text{E}\!\left[ X_i \right]\), as well as asymptotically normal. What can we say about estimators of the form \(g(\bar X)\)?
37.1 Jensen’s Inequality
First of all, \(g(\bar X)\) is not unbiased for \(g(\mu)\) in general. To evaluate \(\text{E}\!\left[ g(\bar X) \right]\), we cannot simply pass the expectation through \(g\); that is, \[ \text{E}\!\left[ g(\bar X) \right] \neq g(\text{E}\!\left[ \bar X \right]). \] The proper way to evaluate \(\text{E}\!\left[ g(\bar X) \right]\) is to use LotUS (Theorem 21.1). However, this requires knowing the exact distribution of \(\bar X\).
Fortunately, there is a way to determine the direction of the bias without evaluating \(\text{E}\!\left[ g(\bar X) \right]\) directly when \(g\) is a convex function.
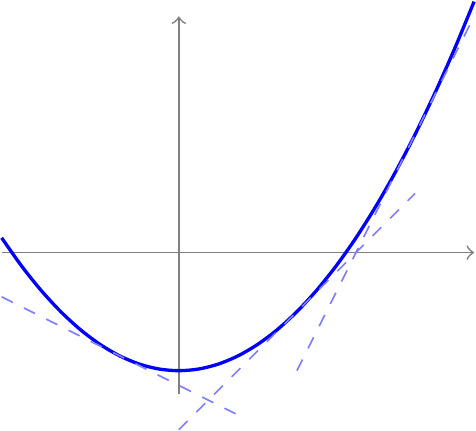
Definition 37.1 (Convex function) A twice-differentiable function \(g(x)\) is called convex on a set \(A\) if \(g''(x) \geq 0\) for all \(x \in A\), or equivalently if it lies above every tangent line. That is, for any \(x_0, x \in A\), \[ g(x) \geq g(x_0) + g'(x_0) (x - x_0). \tag{37.1}\] See Figure 37.1.
We can prove that \(g''(x) \geq 0\) for all \(x\) implies Equation 37.1. To see why, observe that by Taylor’s theorem with remainder, there exists a value \(c\) between \(x\) and \(x_0\) such that \[ g(x) = g(x_0) + g'(x_0) (x - x_0) + \frac{g''(c)}{2} (x - x_0)^2, \] as we wanted to show.
By assumption, \(g''(c) \geq 0\), so \[ g(x) \geq g(x_0) + g'(x_0) (x - x_0). \]
On the other hand, a function \(g(x)\) is concave if \(g''(x) \leq 0\) for all \(x\) or if it always lies below its tangent lines. Note that if \(g(x)\) is concave, then \(-g(x)\) is convex.
Jensen’s inequality describes how expectation behaves under a convex transformation.
Here is a simple application of Theorem 37.1. The function \(g(x) = x^2\) is convex. Therefore, Jensen’s inequality tells us that for any random variable \(X\), \[ \text{E}\!\left[ X^2 \right] \geq \text{E}\!\left[ X \right]^2. \] We can rearrange this inequality to obtain \[ \text{E}\!\left[ X^2 \right] - \text{E}\!\left[ X \right]^2 \geq 0. \] But the left-hand side is just the shortcut formula for \(\text{Var}\!\left[ X \right]\) (Proposition 11.2). Jensen’s inequality in this case simply restates the well-known fact that variance is non-negative.
Armed with Jensen’s inequality, we can easily determine the direction of the bias of \(\hat\lambda\).
37.2 Continuous Mapping Theorem
Although \(g(\bar X)\) is not, in general, unbiased for \(g(\mu)\), it is still consistent. The key result needed to establish consistency is the following.
If we apply Theorem 37.2 to the sample mean \(\bar X\), which is consistent for \(\mu\) by Theorem 28.2, then we obtain the following corollary: \[ g( \bar{X} ) \stackrel{p}{\to} g(\mu). \]
Consistency means that the estimate should be very close to the truth when \(n\) is large. The code below simulates the sampling distribution of the MLE \(\hat\lambda\) when \(n = 1600\) and \(\lambda = 1.5\).
The estimates nearly always come out to within \(0.10\) of the true value, \(\lambda = 1.5\), as predicted by consistency. Perhaps surprisingly, the sampling distribution also appears to be approximately normal. We explore this phenomenon in the next section.
37.3 Delta Method
Even though \(\bar X\) is approximately normal by the Central Limit Theorem (Theorem 36.1), it may come as a surprise that \(g(\bar X)\) is also approximately normal. For example, in Example 36.5, we saw an example where \(Y\) is a normal random variable, but \(g(Y) = e^Y\) was far from normal. The difference here is that \(\bar X\) is not only approximately normal, but also consistent for \(\mu\). These two facts conspire to make \(g(\bar X)\) also approximately normal.
In this section, we derive the asymptotic distribution of \(g(\bar X)\). To fully appreciate the proof, we will need the following technical lemma, which is optional reading.
To derive the asymptotic distribution of \(g(\bar X)\), we essentially do a first-order Taylor expansion: \[ g(\bar X) \approx g(\mu) + g'(\mu) (\bar X - \mu). \] Now, the right-hand side is just a linear transformation of \(\bar X\), which is approximately normal by the Central Limit Theorem (Theorem 36.1). Since linear transformations of a normal random variable result in another normal random variable (Definition 22.4), \(g(\bar X)\) should also be approximately normally distributed. This recipe is called the delta method.
Armed with the delta method, we can determine the asymptotic distribution of the exponential MLE.
Example 37.3 (Asymptotic Distribution of the Exponential MLE) For the exponential distribution, \(\mu = \frac{1}{\lambda}\) and \(\sigma^2 = \frac{1}{\lambda^2}\). Since the MLE is \(\hat\lambda = g(\bar X) = \frac{1}{\bar X}\), \(g'(\mu) = -\frac{1}{\mu^2} = -\lambda^2\).
We can use the delta method (Equation 37.5) to conclude that \[ \sqrt{n}(g(\bar X) - g(\mu)) \stackrel{d}{\to} \text{Normal}(0, \lambda^4 \frac{1}{\lambda^2}), \] or equivalently, \[ \sqrt{n}(\hat\lambda - \lambda) \stackrel{d}{\to} \text{Normal}(0, \lambda^2).\]
Rearranging terms, we see that the asymptotic distribution is \[ \hat\lambda \stackrel{\cdot}{\sim} \text{Normal}(\lambda, \frac{\lambda^2}{n}). \]
Let’s add this normal curve to the histogram from earlier, where \(n=1600\) and \(\lambda=1.5\). It is a very good approximation!
estimates <- replicate(10000, {
x <- rexp(1600, rate=1.5)
1 / mean(x)
})
hist(estimates, breaks=30, freq=FALSE)
curve(dnorm(x, mean=1.5, sd=sqrt(1.5^2 / 1600)),
col="red", add=TRUE)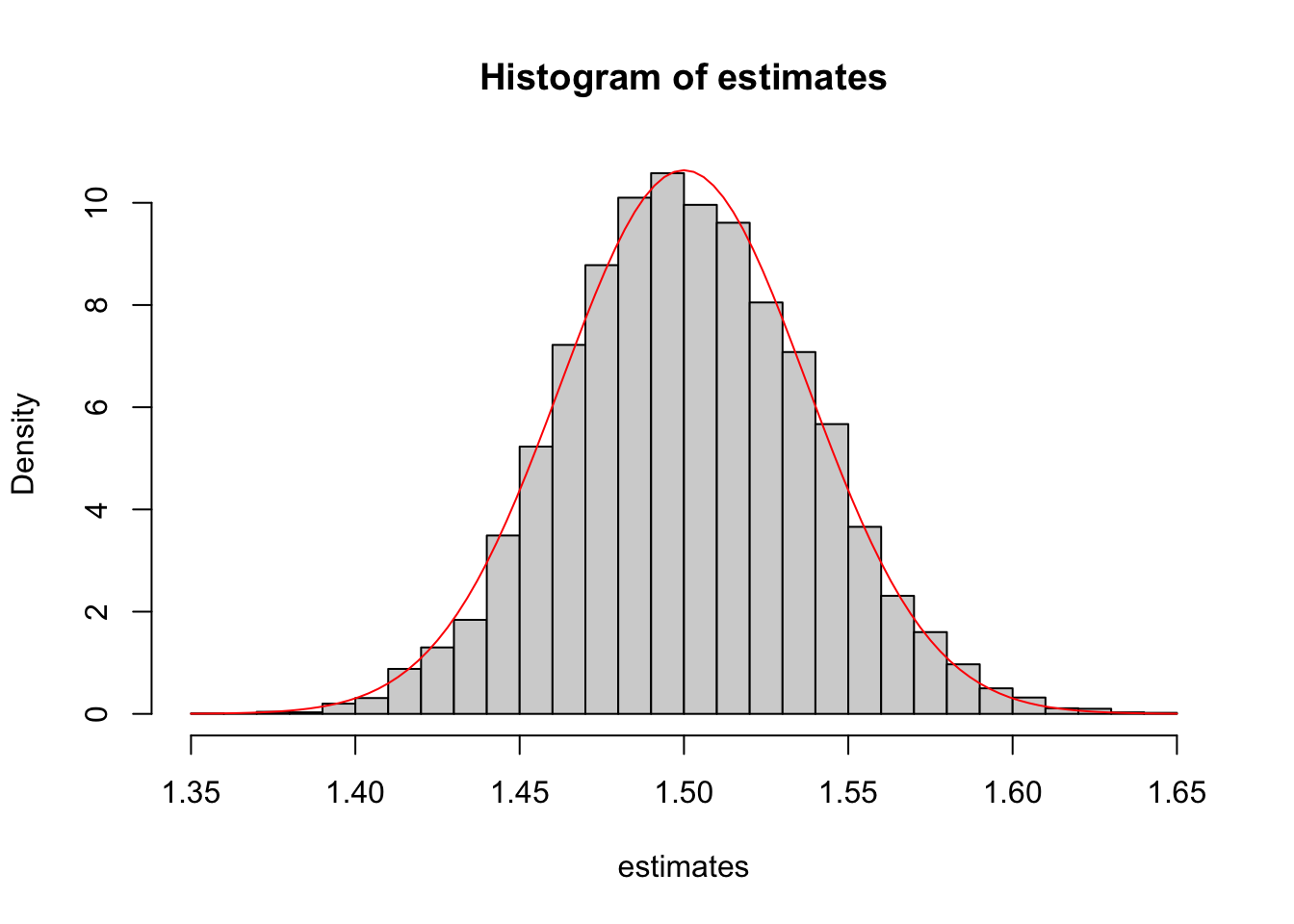
In summary, the MLE of the rate parameter \(\lambda\) from \(n\) i.i.d. exponential observations \[\hat\lambda = \frac{1}{\bar X}\] has positive bias, but this bias is negligible for large \(n\), and \(\hat\lambda\) is asymptotically normal, centered around \(\lambda\).
37.4 Exercises
Exercise 37.1 (Estimating the standard deviation) In Proposition 32.2, we saw that the sample variance \(S^2\) is an unbiased estimator for the variance \(\sigma^2\). But what about an estimator for the standard deviation \(\sigma\)? In this exercise, we will examine how well \(S\) estimates \(\sigma\).
- Show that \(S^2\) is consistent for \(\sigma^2\).
- Show that \(S\) is consistent for \(\sigma\).
- Is \(S\) unbiased for \(\sigma\)? If not, is the bias positive or negative?
Exercise 37.2 (Asymptotic distribution of the geometric MLE) Let \(X_1, \dots, X_n\) be i.i.d. \(\text{Geometric}(p)\).
- Find \(\hat{p}_\textrm{MLE}\), the MLE of \(p\). Use Jensen’s inequality to determine whether it has positive or negative bias.
- Is \(\hat{p}_\textrm{MLE}\) a consistent estimator of \(p\)?
- What is the asymptotic distribution of \(\hat{p}_\textrm{MLE}\)?
- Perform \(N = 10000\) simulations of \(n = 1000\) (as in Example 37.3) and fit a normal curve based on part (c) to verify your work in this problem.
Remark. Note that rgeom counts the number of tails, not the total number of tosses, so it is off by \(1\) with our definition of \(\text{Geometric}(p)\). Adjust accordingly!
Exercise 37.3 (Asymptotic distribution of the squared mean) Let \(X_1, \dots, X_n\) be i.i.d. with \(\text{E}\!\left[ X_1 \right] = \mu \neq 0\) and \(\text{Var}\!\left[ X_1 \right] = \sigma^2\). What does \[ \sqrt{n} \left( \bar{X}^2 - \mu^2 \right) \] converge to (in distribution)? Use this to specify the asymptotic distribution of \(\bar{X}^2\).
Exercise 37.4 (Asymptotic distribution of the odds ratio) Let \(X_1, \dots, X_n\) be i.i.d. \(\text{Bernoulli}(p)\). Suppose we estimate the odds \(\displaystyle \theta = \frac{p}{1-p}\) by \[ \hat\theta = \frac{\bar{X}}{1 - \bar{X}}. \] What is the asymptotic distribution of \(\hat\theta\)?
Exercise 37.5 (Asymptotic distributions of the Rayleigh estimators) In Exercise 31.9, you considered two estimators of \(\sigma^2\) in the Rayleigh distribution (Equation 30.12), the MLE and the method of moments estimator. Derive the asymptotic distributions of both estimators.