11 LotUS and Variance
$$
$$
\[ \def\RR{\textcolor{red}{R}} \def\S{\textcolor{gray}{S}} \]
In Example 9.2, we saw that a $1 bet on a single number and a $1 bet on red in roulette have the same expected profit of \(-\frac{1}{19}\). However, the two bets are very different; we need summaries of a random variable that help us decide between these two bets. In particular, we will develop summaries of the form \(\text{E}\!\left[ g(X) \right]\), where \(g\) is a suitably chosen function.
11.1 Law of the Unconscious Statistician
How do we compute \(\text{E}\!\left[ g(X) \right]\)? To be concrete, suppose, as in Example 10.2 that \(X\) is the price of a stock next week, and we want to calculate the expected value of a call option to buy the stock at a strike price of $55: \[ \text{E}\!\left[ \max(X - 55, 0) \right]. \]
One way to calculate this expectation is suggested by Chapter 10:
- Determine the PMF of \(Y \overset{\text{def}}{=}\max(X - 55, 0)\).
- Calculate \(\text{E}\!\left[ Y \right]\) using Definition 9.1.
However, there is another way, if we appeal to the idea of the expected value as a weighted average.
The fact that the two ways of calculating \(\text{E}\!\left[ g(X) \right]\) agree is a theorem, even though it is intuitive from the definition of expected value. Because many statisticians forget that this fact requires proof, it is sometimes called the “Law of the Unconscious Statistician.”
LotUS underpins Daniel Bernoulli’s expected utility theory, which he developed to resolve the St. Petersburg Paradox (Example 9.6).
Example 11.2 (St. Petersburg Paradox and expected utility) In Example 9.6, we described a game whose payout \(X\) had an infinite expected value, which implies that we should be willing to pay any amount of money to play this game.
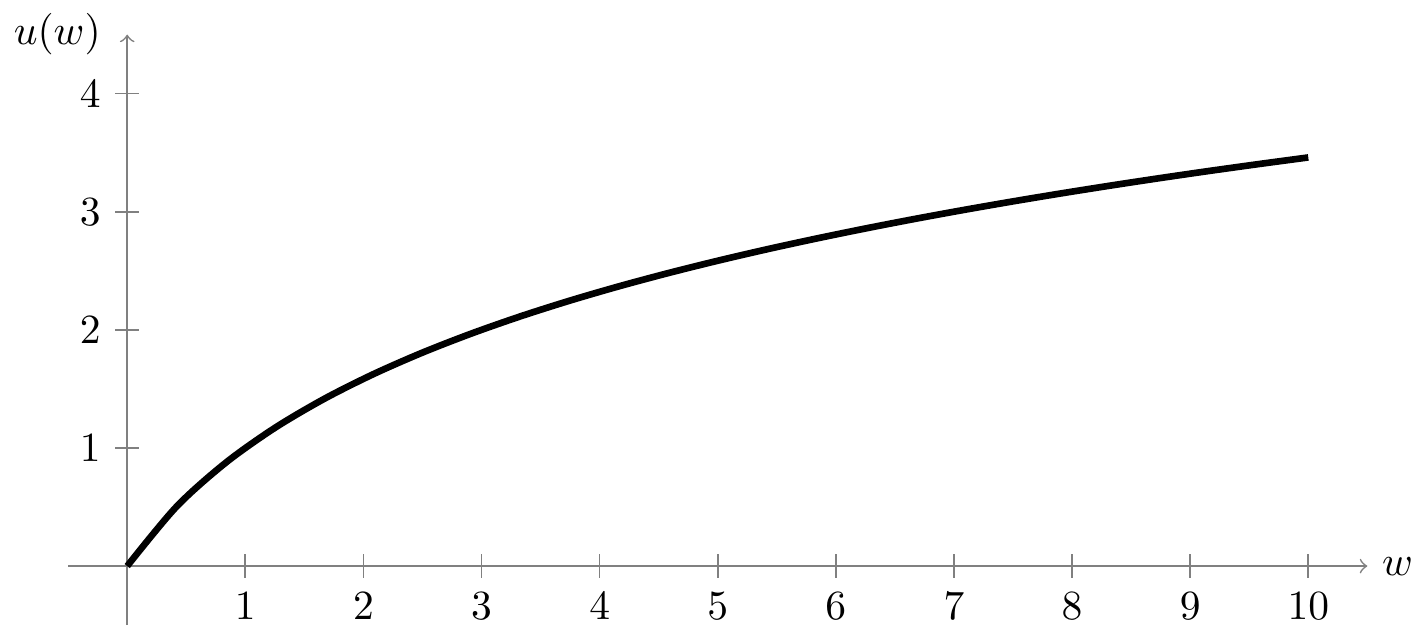
Daniel Bernoulli resolved this paradox by arguing that what matters is not the payout \(X\), but the utility (or “satisfaction”) that we derive from that payout. Because we derive less utility from each additional dollar (an extra dollar means a lot if you only have $10, but not if you are a billionaire), the utility function \(u(w)\) is concave, a property that economists call diminishing marginal utility. An example of a typical utility function is shown in Figure 11.1.
Suppose your utility function is \[ u(w) = \log(w) \] and your current wealth is $100. Then, your options are:
- don’t play this game, in which case your utility is \(u(100) \approx 4.605\) “utils” (the units for utility); or
- pay \(\$c\) to play this game, in which case your utility is \(u(100 - c + X)\).
Bernoulli’s theory says that you should be willing to pay $\(c\) to play if your
expected utility is greater than your utility if you do not play the game: \[
\text{E}\!\left[ u(100 - c + X) \right] > u(100).
\]
To calculate the expected utility, we apply LotUS (Theorem 11.1) to the PMF of \(X\) derived in Example 9.6: \[ \begin{align} \text{E}\!\left[ \log(100 - c + X) \right] &= \sum_{x} \log(100 - c + x) f_X(x) \\ &= \log(101 - c) \cdot \frac{1}{2} + \log(102 - c) \cdot \frac{1}{4} + \log(104 - c) \cdot \frac{1}{8} + \ldots \end{align} \] Although this sum does not have a simple closed-form expression, it is at least finite (for any \(0 < c < 100\)), unlike \(\text{E}\!\left[ X \right]\).
Because the series converges, we can approximate its value by summing the first few terms. The code below calculates the expected utility for a particular value of \(c\). Try changing \(c\). For what values of \(c\) is this expected utility greater than the \(4.605\) utils if you do not play the game?
Expected utility theory suggests that we should only be willing to pay about $4.62 to play this game!
We can also use expected utility to distinguish between the two roulette bets.
There is one situation where we can simply plug in the expected value into the transformation \(g\)—when it is linear, of the form \[ g(X) = aX + b. \] In these situations, we can bypass LotUS.
When the transformation is linear, applying Proposition 11.1 is much easier than applying LotUS.
However, Example 11.4 is more the exception than the rule. In general, LotUS is the foolproof way to calculate an expectation of the form \(\text{E}\!\left[ g(X) \right]\).
11.2 Variance
Another difference between the two roulette bets is how much their outcomes vary. This is captured by the variance, which measures how much the possible outcomes differ from the expected value, as illustrated in Figure 11.2.

We can use Equation 11.3 to calculate the variance of the different roulette bets.
What are the units of variance? In Example 11.5, \(\RR\) was measured in dollars, so \(\text{Var}\!\left[ \RR \right]\) is measured in squared dollars. Because it is often difficult to interpret squared units, it is common to instead report the square root of variance, which is in the same units as the original random variable.
The standard deviations of Example 11.5 are \[ \begin{align} \text{SD}\!\left[ \S \right] &\approx \sqrt{33.2078} \approx \$5.76 & \text{SD}\!\left[ \RR \right] &\approx \sqrt{0.9972} \approx \$1.00, \end{align} \] and note that these standard deviations are measured in dollars.
There is another version of the variance formula that is often easier for computations.
The shortcut formula is easier because usually \(\text{E}\!\left[ X \right]\) is already known, so only \(\text{E}\!\left[ X^2 \right]\) needs to be computed. Let’s apply the shortcut formula to the roulette example from Example 11.5.
In Proposition 9.2, we determined the expectation of a \(\text{Binomial}(n,p)\) random variable \(X\) to be \(\text{E}\!\left[ X \right] = np\). Now, we will use Proposition 11.2 to derive a similar expression for \(\text{Var}\!\left[ X \right]\).
Since a Bernoulli random variable is simply a binomial random variable with \(n = 1\), we see that the variance of a Bernoulli random variable is \(p(1 - p)\).
This derivation is algebraically cumbersome. In Example 15.5, we will present an alternative derivation of the binomial variance that involves less algebra and offers more intuition.
Finally, we present the analog of Proposition 11.1 for variance.
Intuitively, adding \(b\) does not affect the spread of the distribution, which is what variance measures. Since variance is measured in units squared, multiplying by \(a\) scales the variance by a factor of \(a^2\).
Now, we use Proposition 11.4 to provide yet another way of calculating the variance of a roulette bet.
11.3 Exercises
Exercise 11.1 (Expected value of a put option) A “put option” is like a call option (Example 10.2), except that it allows the holder to sell a certain share at the “strike price” at a predetermined time.
Consider a put option that allows you to sell the stock in Example 10.2 at a price of $54 next week. Let \(X\) be the price of the stock next week. The value of this put option is \(\max(54 - X, 0)\).
Calculate the expected value of this put option, \(\text{E}\!\left[ \max(54 - X, 0) \right]\).
Exercise 11.2 (Variance of the number of Secret Santa matches) In Exercise 8.1, you derived the PMF of \(X\), the number of friends in a Secret Santa gift exchange who draw their own name. Calculate \(\text{Var}\!\left[ X \right]\).
Exercise 11.3 (Standard deviations in roulette) Continuing Exercise 8.6 and Exercise 9.5, calculate
- \(\text{SD}\!\left[ X \right]\), the standard deviation of the number of bets Xavier wins.
- \(\text{SD}\!\left[ W \right]\), the standard deviation of Xavier’s profit over the 3 spins.
Exercise 11.4 (St. Petersburg Paradox with modified payouts) In Example 9.6, we analyzed a game based on tossing a fair coin repeatedly, where the amount in the pot doubles each time the coin lands tails, and the game ends (and the amount in the pot is paid out) when the coin lands heads. We showed that the expected payout of this game is \(\infty\).
Now consider the following modification of this game: each time the coin lands heads, the amount in the pot increases by 25%. That is, the pot starts with \(\$1\). If the coin lands heads on the first toss, the pot increases to \(\$1 \cdot 1.25 = \$1.25\); if it lands tails again, then the pot increases to \(\$1 \cdot (1.25)^2 = \$1.5625\); and so on.
- Calculate the expected payout of this game, and show that it is no longer infinite.
- Calculate the variance of the payout of this game.
Exercise 11.5 (Huffman coding) A solar‑powered road‑surface beacon broadcasts exactly one of the \(8\) conditions below every minute via a pay‑per‑byte satellite link. From a winter’s worth of logs the firmware team estimated:
| Symbol | Road‑surface state | Probability |
|---|---|---|
| DRY | Completely dry asphalt | 0.45 |
| DAMP | Damp / recently dried | 0.20 |
| WET | Wet (rain) | 0.12 |
| SNOWY | Packed snow | 0.07 |
| ICY | Ice / black ice | 0.06 |
| CLOSED | Road closed (barriers down) | 0.05 |
| SLUSHY | Slush | 0.03 |
| FLOODED | Standing water / flooded | 0.02 |
Note that the broadcasts are a sequence of binary digits (0s and 1s). For example, the DRY condition might be represented by the code 10100, while FLOODED might be represented by the code 1101.
- If we required that all \(8\) codes have the same length (i.e., the same number of binary digits), what is the minimum length that each code would need to be?
- We can save bits using probability! We can assign shorter codes to more common conditions like DRY and longer codes to less common conditions like FLOODED. One way to design such a code is Huffman coding. Devise a Huffman code for the \(8\) conditions above, calculate the expected length of the code for a randomly chosen condition, and compare it to the length you calculated in part a.
To determine the Huffman code, repeatedly merge the two conditions with the lowest probabilities into a single condition (whose probability is their sum), until only one condition remains. Now, we can draw a tree, starting with the individual conditions as the leaves and merging them into the root. Shown below is the tree corresponding to the probabilities in the table above.
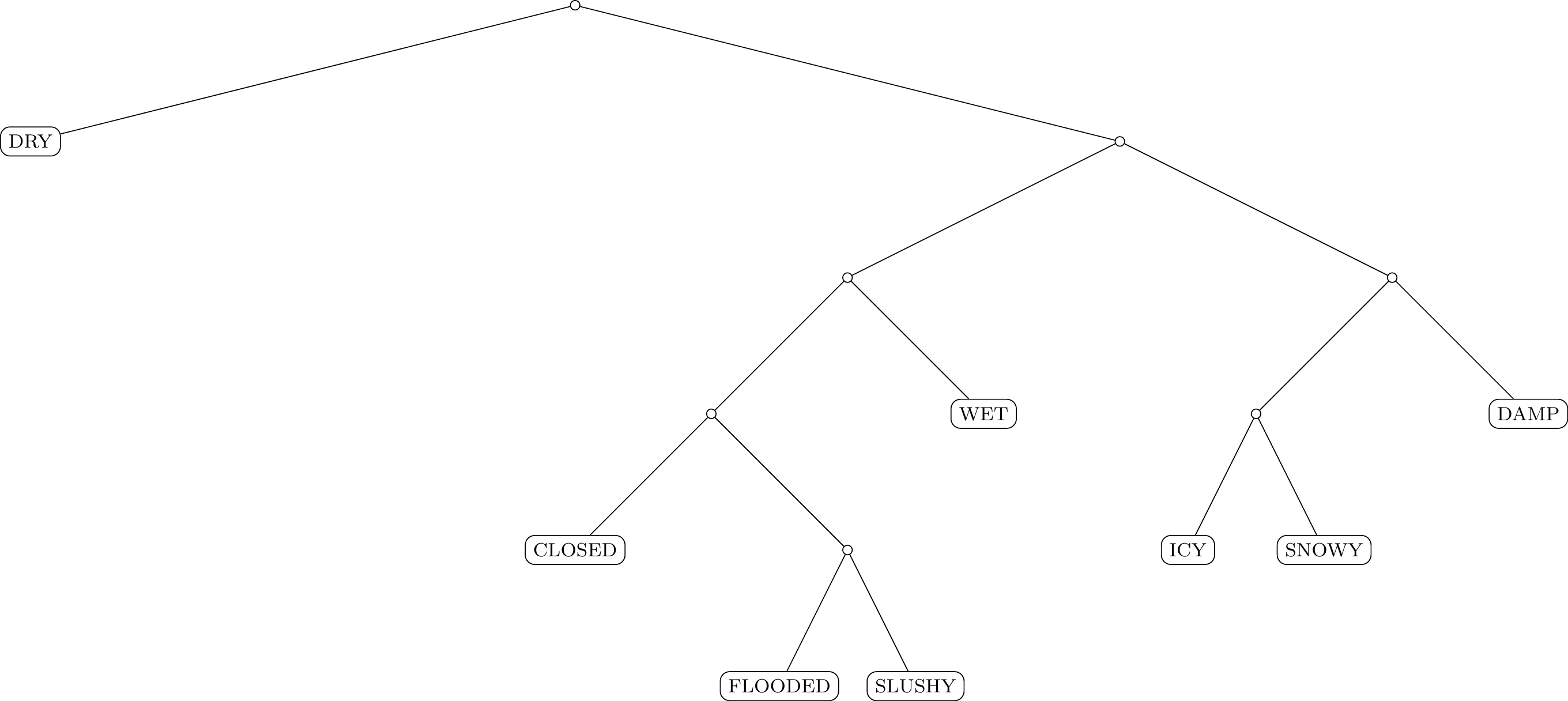
Now, the code for each condition can be determined by tracing the path from the root down to the condition. Each time we take the left branch, we add a 0; each time we take the right branch, we add a 1. For example, based on the tree above,
- the code for WET is
101, - the code for SNOWY is
1101, - and so on.