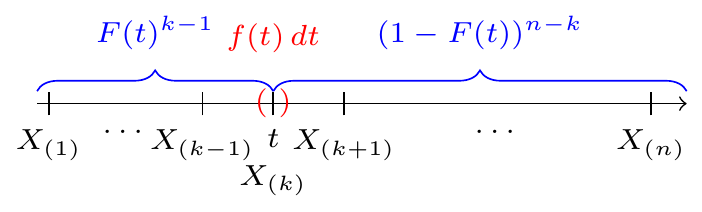
40 General Order Statistics
$$
$$
In Chapter 39, we examined the distribution of the smallest (minimum) and largest (maximum) of \(n\) i.i.d. random variables. In this chapter, we will examine the distribution of the \(k\)th smallest.
For example, if we observe \[ X_1 = 0.87, X_2 = 1.34, X_3 = 0.22, X_4 = 0.36, \] then the order statistics are \[ X_{(1)} = 0.22, X_{(2)} = 0.36, X_{(3)} = 0.87, X_{(4)} = 1.34. \]
Throughout this chapter, we will restrict our attention to order statistics of i.i.d. continuous random variables. The theory for discrete random variables is much more difficult because of the positive probability of ties.
40.1 Distribution of Order Statistics
Proposition 40.1 (Distribution of order statistics) Let \(X_1, \dots, X_n\) be i.i.d. continuous random variables with PDF \(f(x)\) and CDF \(F(x)\). Then, the PDF of the \(k\)th order statistic, \(X_{(k)}\), is \[ f_{X_{(k)}}(t) = n \binom{n-1}{k-1} F(t)^{k-1} f(t) (1 - F(t))^{n-k}. \tag{40.1}\]
Heuristic Proof
In order for \(X_{(k)}\) to be near \(t\), we need \(k-1\) of the \(X_i\)s to be to the left of \(t\) and \(n-k\) of the \(X_i\)s to be to the right. In all, there are \[ \frac{n!}{(k-1)!1!(n-k)!} = n \binom{n-1}{k-1} \] ways to arrange \(X_1, \dots, X_n\) so that the \(k\)th smallest is near \(t\). Then:
- Each of the \(k-1\) smallest random variables has probability \(P(X_i < t) = F(t)\) of being to the left of \(t\).
- Each of the \(n-k\) largest random variables has probability \(P(X_i > t) = 1 - F(t)\) of being to the right of \(t\).
- The \(k\)th smallest observation has probability \(f(t) \, \Delta t\) of being near \(t\).
Hence, the probability that \(X_{(k)}\) is near \(t\) is \[\begin{align*} f_{X_{(k)}}(t) \,\Delta t &\approx P\left( t - \frac{\Delta t}{2} \leq X_{(k)} \leq t + \frac{\Delta t}{2} \right) \\ &\approx n \binom{n-1}{k-1} F(t)^{k-1} (1 - F(t))^{n-k} f(t) \, \Delta t. \end{align*}\] Dividing both sides by \(\Delta t\), we obtain Equation 40.1.
Check that when we set \(k = 1\) or \(k = n\) in Equation 40.1, we recover the PDFs of the minimum and maximum from Chapter 39.
Next, we apply Proposition 40.1 to the median.
In the example above, we numerically approximated the MSE of the median of a random sample of size \(n=9\) from an \(\text{Exponential}(\lambda)\) distribution. The disadvantages of numerical approximation are:
- It is not exact.
- We have to separately calculate the MSE for each value of \(n\).
There is a way to calculate the exact MSE as a function of \(n\), by applying the memoryless property of the exponential distribution. The details are in Exercise 40.5.
Other order statistics besides the median, minimum, and maximum can be useful.
Example 40.2 (Interquartile range) If we observe \(X_1, \dots, X_n\), what is the best way to visualize the data? One way is using a boxplot.
A boxplot displays five order statistics: the minimum, the first quartile, the median, the third quartile, and the maximum. The width of the “box” is the distance between the first and third quartiles, called the interquartile range.
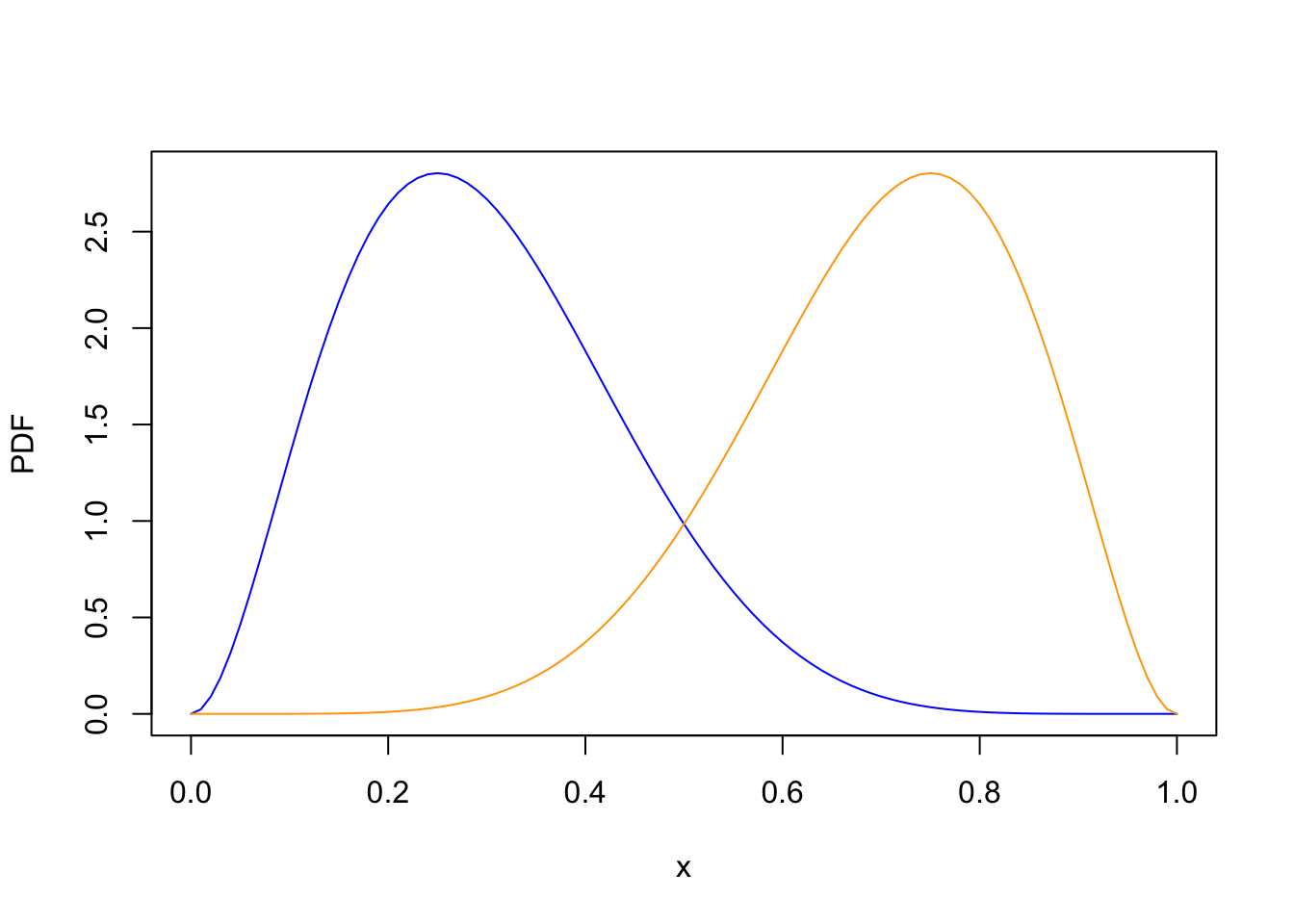
How large is the interquartile range if \(X_1, \dots, X_n\) are i.i.d. \(\textrm{Uniform}(a= 0, b= 1)\)? To be concrete, suppose \(n = 9\) so that the first and third quartiles are \(X_{(3)}\) and \(X_{(7)}\), respectively, and the interquartile range is \(X_{(7)} - X_{(3)}\).
To calculate \(\text{E}\!\left[ X_{(7)} - X_{(3)} \right]\), we need the distributions of \(X_{(3)}\) and \(X_{(7)}\). By Proposition 40.1, the PDF of the \(k\)th order statistic of \(n=9\) i.i.d. standard uniform random variables is \[ f_{X_{(k)}}(t) = 9\binom{8}{k-1} t^{k-1} (1 - t)^{9 - k}. \tag{40.3}\]
The distributions of \(\textcolor{blue}{X_{(3)}}\) and \(\textcolor{orange}{X_{(7)}}\). As expected, the first quartile has most of its mass near \(0.25\), while the third quartile has most of its mass near \(0.75\).
To calculate their exact expected values, we integrate: \[\begin{align} \text{E}\!\left[ X_{(k)} \right] &= \int_0^1 t \cdot 9\binom{8}{k-1} t^{k-1} (1 - t)^{9-k}\,dt \\ &= 9\binom{8}{k-1} \int_0^1 t^k (1 - t)^{9-k} \,dt \\ &= \frac{9\binom{8}{k-1}}{10 \binom{9}{k}} \underbrace{\int_0^1 10 \binom{9}{(k+1)-1} t^{(k+1)-1} (1 - t)^{10-(k+1)} \,dt}_{1} \\ &= \frac{k}{10}. \end{align}\] In the second-to-last line, we recognized the integrand as a PDF of the form Equation 40.1 (with \(10\) and \(k+1\) for \(n\) and \(k\), respectively). Since it is a PDF, it must integrate to \(1\).
Therefore, the expected interquartile range is \[ \text{E}\!\left[ X_{(7)} - X_{(3)} \right] = \text{E}\!\left[ X_{(7)} \right] - \text{E}\!\left[ X_{(3)} \right] = \frac{7}{10} - \frac{3}{10} = 0.4. \]
Note that the true interquartile range for the standard uniform distribution is \[ F^{-1}(0.75) - F^{-1}(0.25) = 0.75 - 0.25 = 0.5, \] so the estimator above underestimates the true interquartile range.
40.2 Joint Distributions of Order Statistics
What about the joint distribution of two or more order statistics? Even if \(X_1, \dots, X_n\) are assumed independent, the corresponding order statistics \(X_{(1)}, \dots, X_{(n)}\) are not independent because each order statistic cannot be less than the previous one. In this section, we derive a formula for the exact joint distribution.
Proposition 40.2 (Joint distribution of two order statistics) Let \(X_1, \dots, X_n\) be i.i.d. continuous random variables with PDF \(f(x)\) and CDF \(F(x)\). Then, the joint PDF of the \(j\)th and \(k\)th order statistics, \(X_{(j)}\) and \(X_{(k)}\), where \(j < k\), is \[ f_{X_{(j)}, X_{(k)}}(t_j, t_k) = \begin{cases} \frac{n!}{(j-1)! (k-j-1)! (n-k)!} F(t_j)^{j-1} f(t_j) (F(t_k) - F(t_j))^{k-j-1} f(t_k) (1 - F(t_k))^{n-k} & t_j < t_k \\ 0 & \text{otherwise} \end{cases}. \tag{40.4}\]
Proof
A rigorous proof is too technical to present here; instead, we will present a heuristic proof similar to the one in Proposition 40.1.
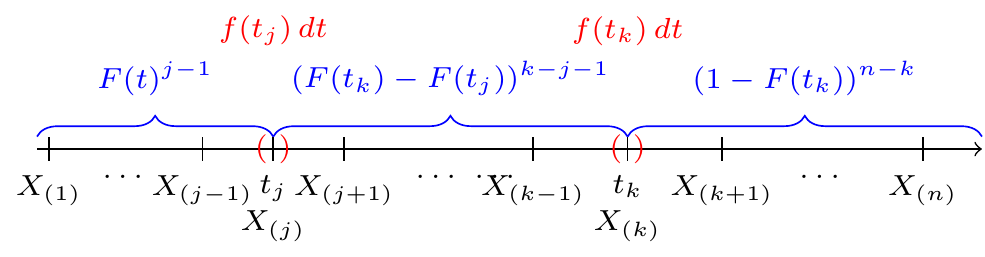
There are \[ \frac{n!}{(j-1)!1!(k-j-1)!1!(n-k)!} \] ways to arrange \(X_1, \dots, X_n\) so that \(j-1\) are to the left of \(t_j\), \(1\) is near \(t_j\), \(k-j-1\) are between \(t_j\) and \(t_k\), one is near \(t_k\), and \(n-k\) are to the right of \(t_k\).
Then, the probability that \(X_{(j)}\) and \(X_{(k)}\) are near \(t_j\) and \(t_k\), respectively, can be approximated as \[\begin{align*} f_{X_{(j)}, X_{(k)}}&(t_j, t_k) \, \Delta t_j \, \Delta t_k \approx P\left( t_j - \frac{\Delta t_j}{2} < X_{(j)} < t_j + \frac{\Delta t_j}{2}, t_k - \frac{\Delta t_k}{2} < X_{(k)} < t_k + \frac{\Delta t_k}{2} \right) \\ &\approx \frac{n!}{(j-1)!1!(k-j-1)!1!(n-k)!} (F(t_j))^{j-1} f(t_j) (F(t_k) - F(t_j))^{k-j-1} f(t_k) (1 - F(t_k))^{n-k} \, \Delta t_j \, \Delta t_k. \end{align*}\] Dividing both sides by \(\Delta t_j \Delta t_k\), we obtain Equation 40.4.
The joint PDF is useful for calculations involving more than one order statistic. For example, the interquartile range from Example 40.2 involves two order statistics, \(X_{(3)}\) and \(X_{(7)}\), so calculating the variance requires their joint distribution.
We can derive the joint distribution of three or more order statistics in the same way. The next result states the joint distribution of all \(n\) order statistics.
40.3 Exercises
Exercise 40.1 Let \(X_1, \dots, X_n\) be i.i.d. \(\text{Uniform}(0,1)\). Compute \[ P\left( X_{(k)} - X_{(k-1)} > t \right) \] for \(1 \leq k \leq n+1\).
Remark. You may assume \(X_{(0)} = 0\) and \(X_{(n+1)} = 1\).
Exercise 40.2 (Median for an even number of observations) Let \(X_1, \dots, X_n\) be i.i.d. continuous random variables. When \(n\) is even, the median is defined as the average of the two middle observations: \[ \frac{X_{\left(\frac{n}{2}\right)} + X_{\left( \frac{n}{2} + 1 \right)}}{2}. \]
Repeat Example 40.1, but for \(n = 10\).
Exercise 40.3 (Estimating the center of the normal distribution) Let \(X_1, \dots, X_7\) be i.i.d. \(\text{Normal}(\mu, \sigma)\). The MLE of \(\mu\) is \(\bar X\), but another estimator of \(\mu\) is the sample median \(X_{(4)}\).
Show that the sample median \(X_{(4)}\) is also unbiased for estimating \(\mu\), and compare its MSE with that of \(\bar X\).
Exercise 40.4 (Estimating the center of the uniform distribution) If we observe i.i.d. random variables \(X_1, \dots, X_n\) from a \(\textrm{Uniform}(a= \theta - 1, b= \theta + 1)\), how do we estimate the center \(\theta\)? For simplicity, we will assume that \(n\) is odd.
- First, let \(U_1, \dots, U_n\) be i.i.d. \(\textrm{Uniform}(a= 0, b= 1)\). Calculate the expectation and variance of the mean \(\bar U\), median \(U_{\left( \frac{n+1}{2} \right)}\), and the midrange \(\displaystyle \frac{U_{(1)} + U_{(n)}}{2}\).
- Now, let \(X_1, \dots, X_n\) be i.i.d. \(\textrm{Uniform}(a= \theta - 1, b= \theta + 1)\). Calculate the MSEs of the mean \(\bar X\), median \(X_{\left( \frac{n+1}{2} \right)}\), and the midrange \(\displaystyle \frac{X_{(1)} + X_{(n)}}{2}\) for estimating \(\theta\). Which estimator is best?
Hint: Let \(X_i = 2 U_i + \theta - 1\) so that you can use the results from part a.
Exercise 40.5 (Exact formula for the MSE of the median) In Example 40.1, we numerically approximated the MSE of the median of a random sample from an \(\text{Exponential}(\lambda)\) distribution. Here is a way to derive the exact formula for the MSE of the median in terms of \(n\).
- Argue that \(X_{(1)}\) and \(X_{(2)} - X_{(1)}\) are independent. What are their distributions? (Hint: Use the result of Example 39.4 and the memoryless property of the exponential distribution.)
- In fact, continuing this argument shows that \(X_{(1)}, X_{(2)} - X_{(1)}, X_{(3)} - X_{(2)}, \dots\) are mutually independent. Use this to calculate \(\text{E}\!\left[ X_{\left(\frac{n+1}{2}\right)} \right]\) and \(\text{Var}\!\left[ X_{\left(\frac{n+1}{2}\right)} \right]\). (Hint: Your answer will be in the form of a summation.)
- Calculate the MSE of the median for estimating the median of the exponential distribution. Your answer should be a function of \(n\) and \(\lambda\). Simplify as much as possible, but leave your final answer in terms of summations.