26 From Conditionals to Marginals
$$
$$
In Chapter 16, we considered situations where the distribution of two discrete random variables \(X\) and \(Y\) was specified by
- first specifying the PMF of \(X\),
- then specifying the conditional PMF of \(Y\) given \(X\).
We saw that the (marginal) PMF of \(Y\) could be calculated using the Law of Total Probability (Theorem 7.1) \[ f_Y(y) = \sum_x f(x, y) = \sum_x f_X(x) f_{Y|X}(y|x). \tag{26.1}\]
We now generalize Equation 26.1 to the situation where \(X\) or \(Y\) may be continuous.
26.1 Laws of Total Probability
As a warm-up, we revisit Example 23.7, where \(X\) and \(Y\) represent the times that you and a friend have to wait to enter an amusement park. We assumed that \(X\) and \(Y\) were independent \(\text{Exponential}(\lambda_1)\) and \(\text{Exponential}(\lambda_2)\) random variables, respectively. Previously, we calculated \(P(X < Y)\) using a double integral. Now, we show how to calculate this probability using the Law of Total Probability.
Example 26.1 reinforces a point we made after Example 23.7. Double integrals are rarely the most intuitive way to solve most real problems in probability and statistics. If you think carefully about the structure of a problem, you can usually avoid double integrals (or calculus altogether)!
Now, we are ready to state the general version of the Law of Total Probability. In fact, there are many versions, depending on whether \(X\) and \(Y\) are discrete or continuous.
In Chapter 16, we saw several applications of Proposition 26.1 when \(X\) and \(Y\) are both discrete. So we focus on the other possibilities in the examples below. In the first example, the random variable we are conditioning on, \(I\), is discrete, so Equation 26.3 applies.
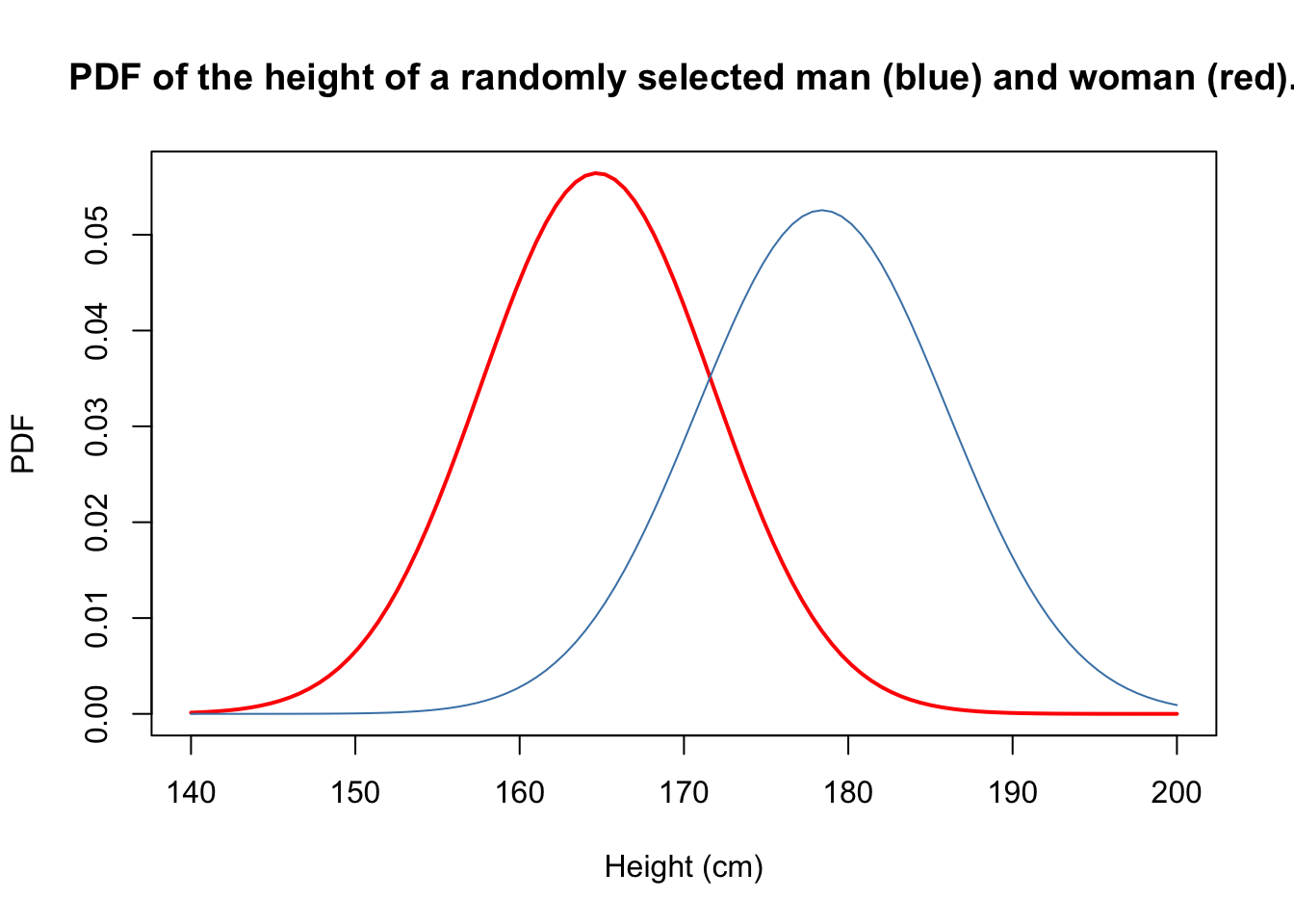
Example 26.2 (Sexual dimorphism) In biology, sexual dimorphism refers to morphological differences between males and females of the same species. One common example is human height. Data shows that the heights of adult human males and females are approximately normally distributed, but with different means and variances. (Jelenkovic et al. 2016)
Let \(I\) be an indicator variable for the event that a randomly selected person is female. Then the height \(H\) of the selected adult has the following conditional distributions:
\[ \begin{align} H \mid \{ I = 0 \} &\sim \textrm{Normal}(\mu= 178.4 \text{ cm}, \sigma^2= 7.59^2 \text{ cm}^2) \\ H \mid \{ I = 1 \} &\sim \textrm{Normal}(\mu= 164.7 \text{ cm}, \sigma^2= 7.07^2 \text{ cm}^2). \end{align} \]
These distributions are graphed below.
Human populations tend to be skewed towards males: \[ f_I(0) = P(I = 0) = 0.51, \quad f_I(0) = P(I = 1) = 0.49. \]
The general Law of Total Probability (Proposition 26.1) says that the marginal PDF of \(H\) is \[\begin{align*} f_H(h) &\approx f_I(0) \cdot f_{H \mid I}(h \mid 0) + f_I(1) \cdot f_{H \mid I}(h \mid 1) \\ &= 0.51 \cdot \frac{1}{\sqrt{2\pi \cdot 7.59^2}} \exp\left( -\frac{(h - 178.4)^2}{2 \cdot 7.59^2} \right) \\ &\quad + 0.49 \cdot \frac{1}{\sqrt{2\pi \cdot 7.07^2}} \exp\left( -\frac{(h - 164.7)^2}{2 \cdot 7.07^2} \right). \end{align*}\] Note that \(H\) is continuous, so both \(f_H(h)\) and \(f_{H\mid I}(h\mid i)\) are PDFs.
The figure below shows what the PDF of \(H\) looks like.
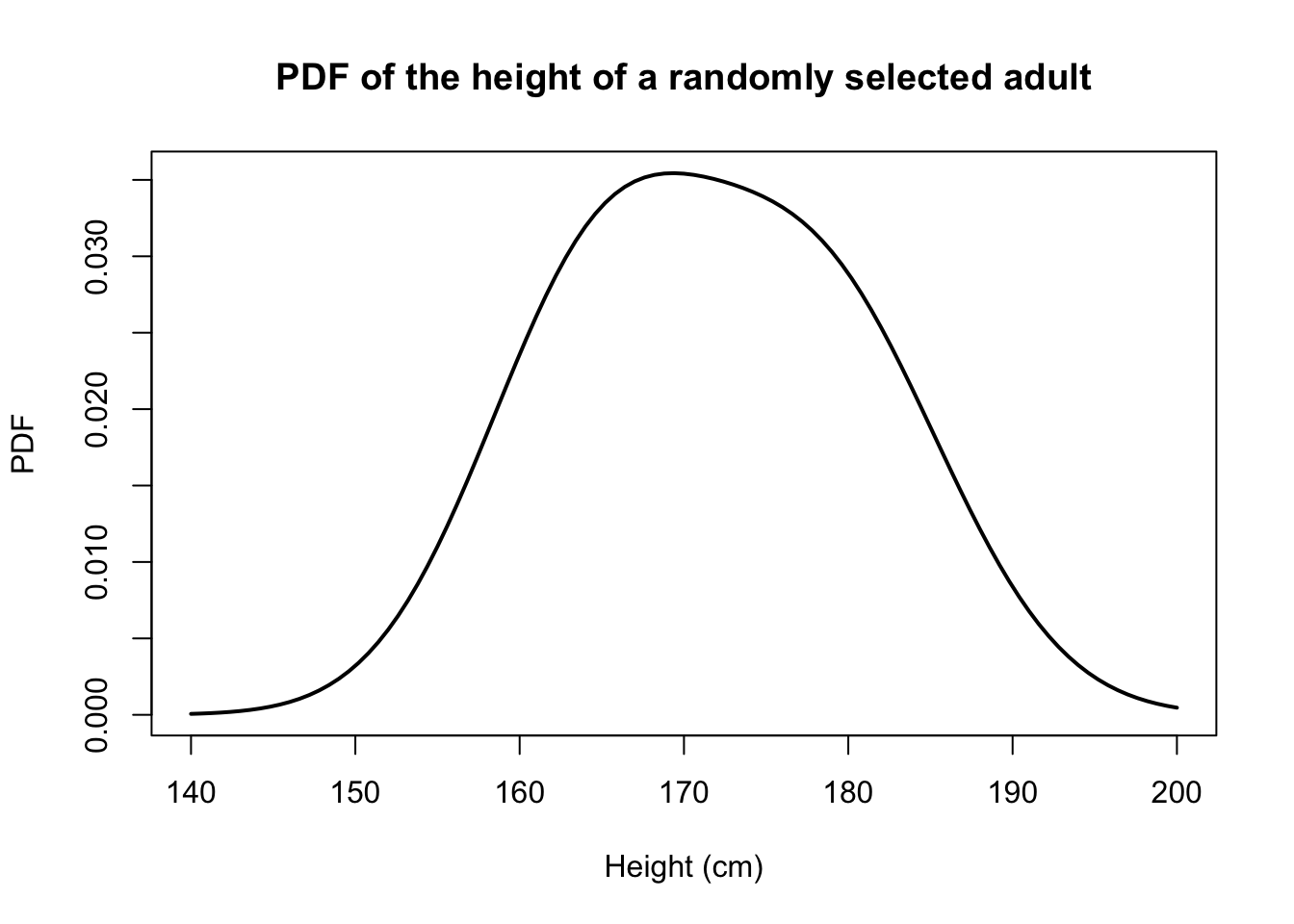
Notice that this distribution is not normal. Instead, it is a mixture of two different normal distributions.
In the next example, the random variable we are conditioning on, \(S\), is discrete, so Equation 26.4 applies.
Example 26.3 (Free throws in basketball) A person is chosen at random from the population and asked to shoot \(n\) basketball free throws. Let \(X\) be the number of free throws that person makes. What is the distribution of \(X\)?
Each person has a different probability of making a free throw, depending on their skill. Since the person is chosen at random, this skill is a random variable \(S\). Suppose we model \(S\) as a \(\textrm{Uniform}(a= 0, b= 1)\) random variable. (All skill levels are equally likely.)
Conditional on \(S\), it seems reasonable to assume that the \(n\) free throws are independent, so \[ X | \{ S = s \} \sim \text{Binomial}(n, p=s). \]
But what is the marginal distribution of \(X\)? We can use the Law of Total Probability, conditioning on the skill \(S\) of the person we selected: \[ \begin{align} f_X(x) &= \int_{-\infty}^\infty f_S(s) f_{X|S}(x|s)\,ds \\ &= \int_0^1 1 \cdot \binom{n}{x} s^x (1 - s)^{n-x} \,ds; & x=0, 1, \dots, n. \end{align} \tag{26.5}\] Note that \(X\) is discrete, so both \(f_X(x)\) and \(f_{X\mid S}(x\mid s)\) are PMFs.
This integral is a polynomial in \(s\), so it is straightforward to evaluate for any particular values of \(n\) and \(x\). However, it is not obvious how to devise a general formula.
In the same paper that introduced Bayes’ rule, Thomas Bayes (1763) devised a clever way to evaluate Equation 26.5. He imagined \(n+1\) balls being rolled across a table. (Later writers interpreted these to be billiards balls on a pool table.) Suppose that each of these balls is equally likely to land anywhere on the opposite side, independently of the other balls. If the opposite side has length \(1\), then the position of the balls are independent \(\textrm{Uniform}(a= 0, b= 1)\) random variables. To map this situation onto the model above,
- let \(S\) be the position of the initial ball, and
- let \(X\) be the number of the remaining \(n\) balls that lie to the left of the initial ball. Conditional on the position of the initial ball \(\{ S = s \}\), each ball has a probability \(s\) of being to the left, and the balls are independent by assumption. Therefore, \(X | \{ S = s\}\) is binomial.
This situation is illustrated in Figure 26.1 for \(n=6\).
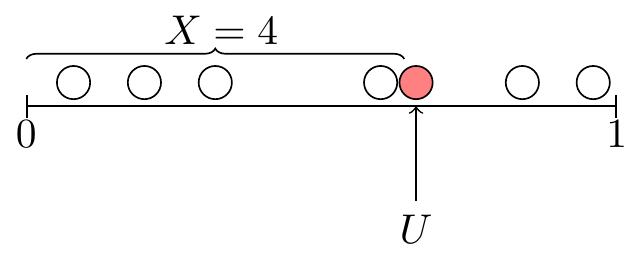
What is the marginal distribution of \(X\)? Since the \(n+1\) balls are identical, they are all equally likely to be the initial ball. If the initial ball is the leftmost ball, then \(X = 0\); if it is the rightmost ball, then \(X = n\); all values in between are equally likely. Therefore, \[ f_X(x) = \frac{1}{n+1}; \qquad x=0, 1, \dots, n. \tag{26.6}\]
If Bayes’ argument seems too clever, we will see a more straightforward way to show that the integral in Equation 26.5 is equal to Equation 26.6 in Chapter 41, after developing more machinery.
26.2 Bayes’ Rule
Recall from Theorem 7.2 that Bayes’ rule allows us to compute \(P(B \mid A)\) from \(P(A \mid B)\). Bayes’ rule can be generalized to random variables; it allows us to determine the distribution of \(X \mid Y\) from the distribution of \(Y \mid X\).
Proposition 26.2 is especially useful when one random variable is observable, but the other is not. For example, in Example 26.3, it is easy to observe \(X\), the number of free throws made, but it is difficult to observe \(S\), the skill of the person taking the free throws. In this case, we can use Bayes’ rule to make inferences about \(S\), given \(X\).
Example 26.4 (Inferring skill from free throws) Continuing with Example 26.3, suppose the randomly selected person shoots \(n = 18\) free throws and makes \(X = 12\) of them. What can we infer about their skill \(S\)?
Before we watched this person take free throws, \(S\) was equally likely to be \(0\) and \(1\). This is our prior belief about their skill level. In light of the information that they made two-thirds of their \(18\) free throws, we should update our belief about their skill.
To make this precise, we determine the conditional PDF of \(S\) given \(X\) via Proposition 26.2.
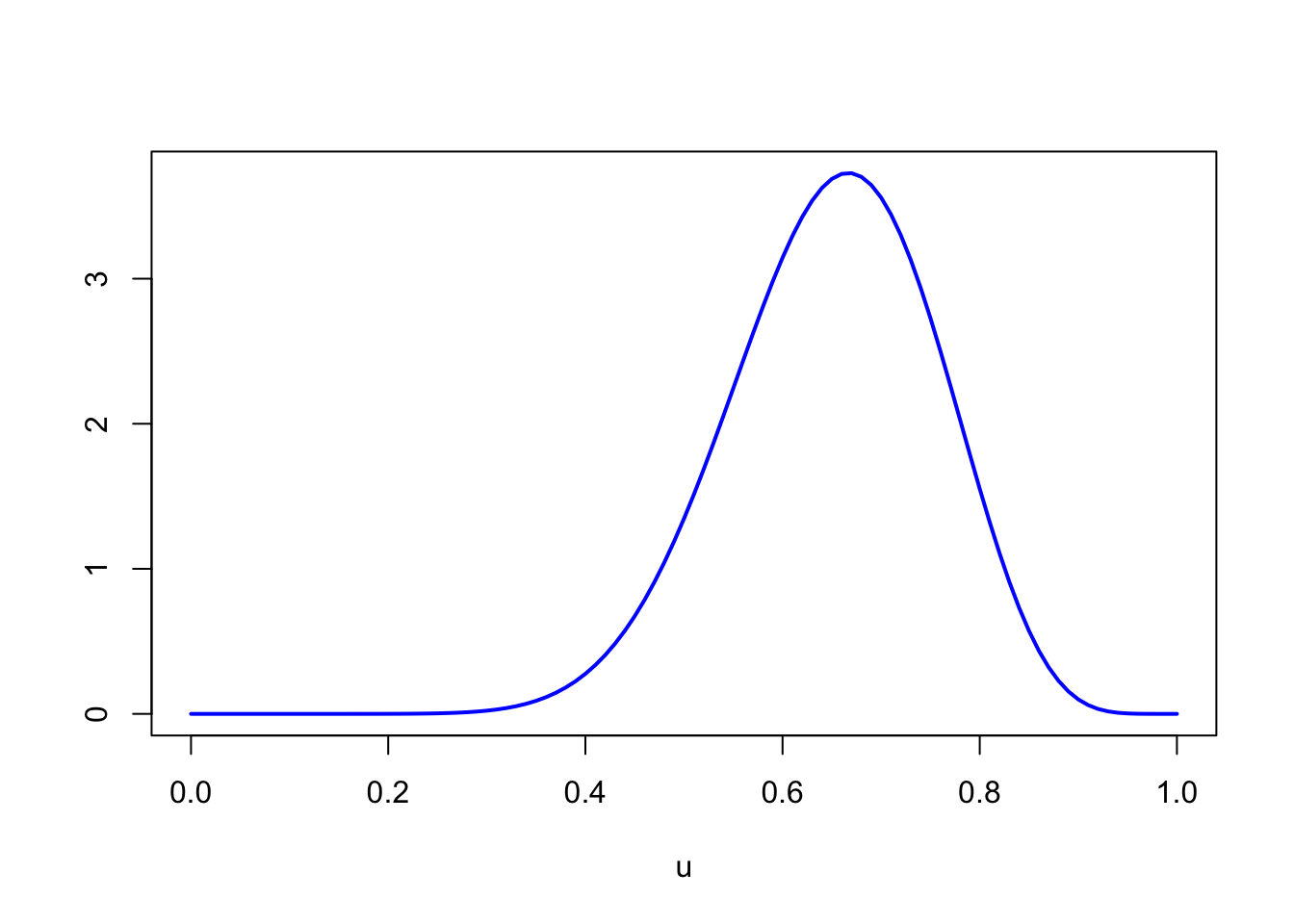
\[ \begin{align} f_{S|X}(s|x) &= \frac{f_S(s) f_{X|S}(x|s)}{f_X(x)} \\ &= \frac{1 \cdot \binom{n}{x} s^x(1-s)^{n-x}}{\frac{1}{n+1}} \\ &= (n+1) \binom{n}{x} s^x (1 - s)^{n-x} \end{align} \] for \(0 < s < 1\) and \(x = 0, 1, \dots n\).
Substituting in \(n=18\) and \(x=12\), the conditional distribution of \(S\) is \[ f_{S|X}(s|12) = 19 \binom{18}{12} s^{12} (1 - s)^6; \qquad 0 < s < 1. \]
This PDF is graphed below. This represents our updated, or posterior, belief about their skill level, as a result of the observed data.
26.3 Exercises
Exercise 26.1 (Modeling car accidents) Suppose that the number of car accidents in a year for a driver in a population is a \(\text{Poisson}(\mu)\) random variable, where \(\mu\) is a parameter that varies from driver to driver and describes a driver’s proneness to accidents. Suppose further that \(\mu\) follows an \(\text{Exponential}(\lambda)\) distribution.
- Find the marginal PMF of the number of accidents for a randomly selected driver.
- Suppose that a randomly selected driver has no accidents for the year. Find the conditional PDF of \(\mu\) given this information.
Exercise 26.2 (Modeling IQ) The true intelligence quotient (IQ) \(\mu\) of a randomly selected individual is a normally distributed random variable with mean 100 and standard deviation 15. However, we cannot observe \(\mu\) directly. Instead, we can only measure an individual’s score on an IQ test, which is normally distributed around \(\mu\) with standard deviation \(5\).
- Find the marginal PDF of the IQ score of a randomly selected individual.
- Suppose that a randomly selected individual scores 120 on an IQ test. Find the conditional PDF of \(\mu\) given this information.