29 Probability versus Statistics
In the introduction to this unit, we discussed the importance of estimation. This chapter introduces the problem of estimation by considering the relationship between probability and statistics.
29.1 Mark-Recapture
We introduced mark-recapture in Example 12.3 as a method for estimating the size of a population, such as the number of snails in a state park. First, we capture a sample, say \(50\) snails, and “mark” them. Then, after some time, we recapture another sample of snails, say \(40\). Some of these snails will be marked from the first capture, while the rest are unmarked. In Chapter 12, we learned to solve probability problems like the following.
But Example 12.3 is unrealistic. If we knew that there were \(300\) snails in the population, we would not bother doing mark-recapture in the first place!
Here is a more realistic problem, where we have collected data and want to infer something about the population.
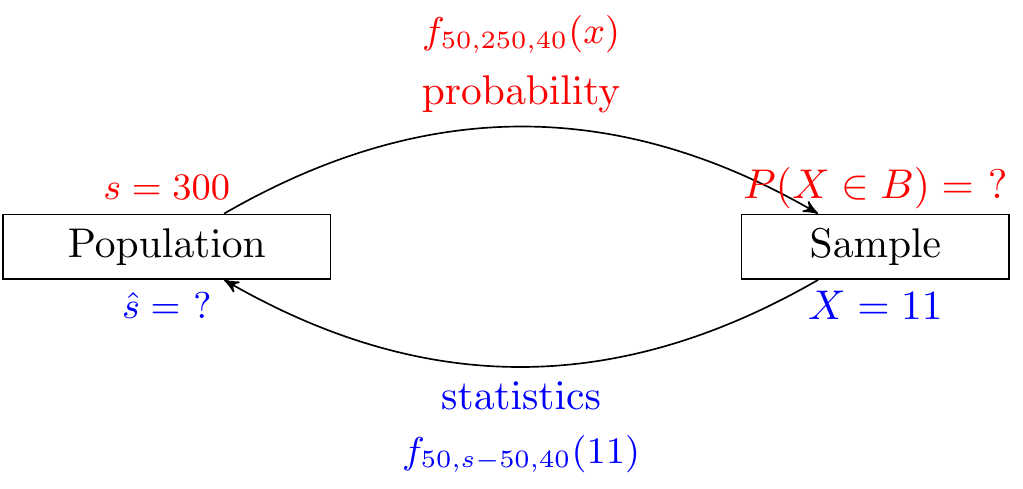
In Example 12.3, we assumed that \(N = 300\) and wanted to calculate the probabilities of various values of \(X\), whereas in Example 29.1, we observe \(X = 11\) and want to estimate \(N\). In other words, statistics is the inverse of probability. This idea is illustrated in Figure 29.1.
Properties of the population (or model), such as \(N\), are called parameters, while properties of the sample (or data), such as \(X\), are called statistics. How do we estimate a parameter using data? The probability distribution still plays an important role. However, the unknown quantity is now the parameter \(N\), instead of the value of the random variable \(X\). This motivates the following definition:
Let us determine the likelihood for the mark-recapture problem.
How do we use the likelihood to estimate \(N\)? Since the likelihood represents the probability of observing the data, one idea is to choose \(N\) to make this probability as large as possible. This principle is stated below.
To find the MLE for the mark-recapture problem, we find the value of \(N\) that maximizes \(L_{11}(N)\). From Example 29.2, we see that the likelihood is maximized somewhere between 150 and 200. To determine the exact value, we print out the likelihood for all values of \(N\) between 150 and 200.
We see that the likelihood is maximized at \(N = 181\), where it achieves a maximum value of \(0.15854\). Therefore, the MLE for the size of the snail population is \(\hat N = 181\). This value makes intuitive sense. The data suggests that approximately \(11 / 40 = 0.275\) of all snails are marked. Since we marked \(50\) snails, the number of snails in the population should be \(50 / 0.275 \approx 181.82\), which is very close to the MLE.
This is no accident. We can derive the MLE as a function of the total number of marked snails \(M\), the number of snails in the second sample \(n\), and and the number of marked snails in the second sample \(x\). To do this, we consider the ratio \(L_x(N) / L_x(N - 1)\):
\[ \begin{align} \frac{L_x(N)}{L_x(N - 1)} &= \frac{\frac{\binom{M}{x} \binom{N - M}{n - x}}{\binom{N}{n}}}{\frac{\binom{M}{x} \binom{N - 1 - M}{n - x}}{\binom{N - 1}{n}}} \\ &= \frac{(N - n)(N - M)}{N(N - M - n + x)}. \end{align} \]
The likelihood is increasing if and only if this ratio is greater than \(1\)—that is, when \[ \begin{align*} (N - n)(N - M) &> N(N - M - n + x) \\ N^2 - NM - nN + nM &> N^2 - NM - nN + Nx \\ nM &> Nx. \end{align*} \] In other words, the likelihood will increase as long as \(N < \frac{nM}{x}\), and it will decrease when \(N > \frac{nM}{x}\). Therefore, the likelihood is maximized when \(N\) is the greatest integer not exceeding \(\frac{nM}{x}\): \[ \hat N = \left\lfloor \frac{nM}{x} \right\rfloor. \]
This captures the intuition that the best estimate of the population size is the value of \(N\) that makes \(\frac{M}{N} \approx \frac{x}{n}\).
29.2 Skew Dice
A skew die is one whose faces are irregular. Are skew dice fair? One way to find out is to roll the die and collect some data.

You should already be familiar with how to solve problems like the following.
But the whole point of rolling the die is to determine the probability of landing on each face. That is, the statistics question is likely more compelling than the probability question.
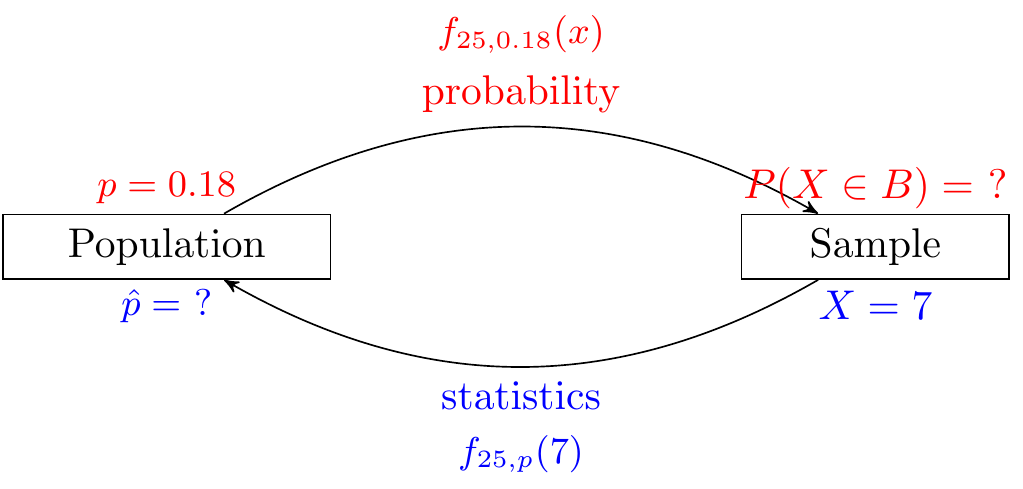
The MLE in Example 29.4 is intuitive. If the skew die landed on six \(7\) times in \(25\) rolls, then our best estimate for the probability of landing on six is \(\frac{7}{25}\). We can show this fact more generally, by replacing \(25\) by \(n\) and \(7\) by \(x\).
The likelihood of \(p\) is \[ L_x(p) = \binom{n}{x} p^x (1 - p)^{n - x}. \] As above, taking the derivative with respect to \(p\), we obtain \[ \begin{align} 0 &= \frac{\partial}{\partial p} L_x(p) \\ &= \frac{\partial}{\partial p} \binom{n}{x} p^x (1 - p)^{n - x} \\ &= \binom{n}{x} \big(x p^{x - 1} (1 - p)^{n - x} - (n - x) p^x (1 - p)^{n - x - 1}\big) \\ &= \binom{n}{x} p^{x - 1} (1 - p)^{n - x - 1} \big(x (1 - p) - (n - x) p\big). \end{align} \] The solution to this equation corresponding to a maximum is \[ \hat p = \frac{x}{n}. \]
29.3 Exercises
Exercise 29.1 Suppose \(X\) is a discrete random variable with \(P(X = 7) = p\) and \(P(X = 8) = 1-p\). Three independent observations are made: \(x_1 = 7\), \(x_2 = 8\), and \(x_3 = 7\). What is the MLE of \(p\)?
Exercise 29.2 (MLE of the free throw percentage) Your friend claims to be an excellent free throw shooter. You are skeptical, so they tell you that the last time they practiced their free throws, they made seven in a row before missing their eighth. Assuming the free throws are independent and your friend had the same probability \(p\) of making each one,
- Plot the likelihood as a function of \(p\).
- Calculate the maximum likelihood estimate of \(p\).
Exercise 29.3 (Poisson MLE) Let \(X \sim \text{Poisson}(\mu)\). Suppose we observe \(X = x\). What is the MLE of \(\mu\) (in terms of \(x\))?
Exercise 29.4 (MLE of the number of trials) Suppose you toss a coin \(n\) times, but you lose track of how many times you flipped the coin. However, you know the coin has a probability \(p\) of landing heads, and you recall counting \(k\) heads. What is the MLE of \(n\)?
Exercise 29.5 (Simple random sampling) You are interested in the proportion of students at a university who own a dog. Suppose that there are \(N = 7500\) students at the university, and you randomly ask \(n = 130\) students (without replacement) whether or not they own a dog. This is called a simple random sample of size \(n\) from the population (of size \(N\)).
You find that \(X = 60\) of the \(n = 130\) students in your sample own a dog. Based on this information, what is the MLE of \(p\), the proportion of students who own a dog?
Hint: If \(M\) is the number of students at the university who own a dog, then \(p = \frac{M}{N}\). It may help to find the MLE of \(M\) first. You can do this using R or using algebra, as in Section 29.1.
Exercise 29.6 (Hardy-Weinberg principle) The Hardy-Weinberg principle predicts the frequency of genetic variants in a population in equilibrium.
For example, in the MN blood group system, there are two alleles, M and N, so each person’s blood type is either MM, MN, or NN. If \(p\) is the frequency of allele M (and \(1 - p\) is the frequency of allele N), then the Hardy-Weinberg principle predicts that the three blood types occur with the following frequencies:
| MM | MN | NN |
|---|---|---|
| \(p^2\) | \(2p(1 - p)\) | \((1 - p)^2\) |
In a sample of \(n=1029\) people from the Chinese population of Hong Kong in 1937, it was observed that the blood types occurred in the following frequencies.
| MM | MN | NN |
|---|---|---|
| \(342\) | \(500\) | \(187\) |
Using this data, calculate the maximum likelihood estimate of \(p\), the frequency of allele M in the Chinese population of Hong Kong.