5 Conditional Probability
$$
$$
You walk by a roulette wheel at a casino (Figure 1.5) and stop to watch. The ball lands in a red pocket on \(9\) spins in a row. You wonder if you should enter the action at this point, betting on black. After all, the probability of \(10\) reds in a row is very small, only \[ P(\text{all 10 spins are red}) = \frac{18^{10}}{38^{10}} \approx 0.00057. \tag{5.1}\] In particular, it is much lower than the probability of \(1\) black and \(9\) reds in the \(10\) spins: \[ P(\text{1 black, 9 reds in 10 spins}) = \frac{{10 \choose 1} 18^{1}18^{9}}{38^{10}} \approx 0.0057 \]
Where is the flaw in this argument? The calculations are correct; the problem is that these probabilities are not relevant to the decision you want to make. The \(9\) reds have already happened, so there is no reason to calculate their probability. Instead, we should be using this information to update the probability that the 10th spin is red. We write this updated probability as \[ P(\text{10th spin is red}\ |\ \text{first 9 spins are red}), \tag{5.2}\] called a conditional probability. This is more relevant to your decision than the joint probability (Equation 5.1).
In this chapter, we will discuss how to calculate conditional probabilities, as a way to update probabilities in light of new information. By the end of this chapter, we will be able to calculate Equation 5.2 and answer the question of whether you should bet on black.
5.1 Definition of Conditional Probability
To motivate the definition of conditional probability, we recall the Secret Santa example (Example 1.7). Four friends write their names on slips of paper, put the slips in a box, shake the box, and each draw a name. Now suppose that after drawing the first slip, the first friend announces that she did not draw her own name. How does this information change the probability that the second friend draws his own name?
Representing each friend with a number from 1 to 4 (as we did in Example 1.7), we recall the \(24\) equally likely outcomes in our sample space. Bolded entries are the outcomes where the second friend draws his own name:
| 1. 1234 | 7. 2134 | 13. 3124 | 19. 4123 |
| 2. 1243 | 8. 2143 | 14. 3142 | 20. 4132 |
| 3. 1324 | 9. 2314 | 15. 3214 | 21. 4213 |
| 4. 1342 | 10. 2341 | 16. 3241 | 22. 4231 |
| 5. 1423 | 11. 2413 | 17. 3412 | 23. 4312 |
| 6. 1432 | 12. 2431 | 18. 3421 | 24. 4321 |
We see that, initially, the probability of the second friend drawing his own name is \(6/24 = 0.25\), which makes sense because of symmetry.
However, upon learning that the first friend did not draw her own name, we can remove all outcomes where she does, leaving us with a reduced, but still equally likely, set of possible outcomes:
| 7. 2134 | 13. 3124 | 19. 4123 | |
| 8. 2143 | 14. 3142 | 20. 4132 | |
| 9. 2314 | 15. 3214 | 21. 4213 | |
| 10. 2341 | 16. 3241 | 22. 4231 | |
| 11. 2413 | 17. 3412 | 23. 4312 | |
| 12. 2431 | 18. 3421 | 24. 4321 |
The second friend only draws his own name in \(4\) of the remaining outcomes, so the probability that he draws his own name has decreased to \(4/18 \approx 0.222\). This result makes sense: if the first friend did not draw her own name, then she is more likely to have drawn the second friend’s name. This should reduce the chance that the second friend draws his own name.
This is an example of a conditional probability. The conditional probability \(P(A|B)\) (read as “probability of \(A\) given \(B\)”) is the probability of \(A\) happening if we know that \(B\) has happened. As we saw above, knowing that \(B\) has happened gives important partial information about the experiment’s outcome (i.e., we know it must be in \(B\)), forcing us to update our assessment of how likely \(A\) is to happen.
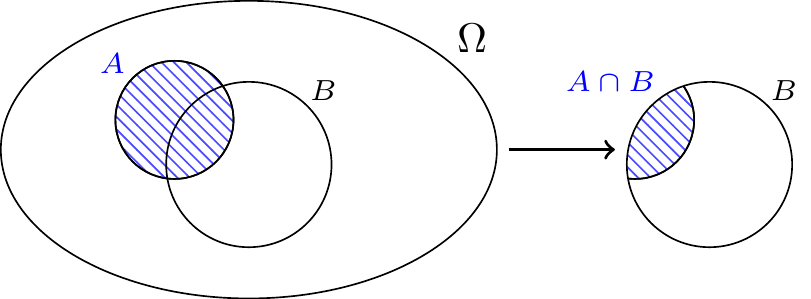
Before giving a formal definition of conditional probability, we first motivate it visually in Figure 5.1. This diagram illustrates how the event \(A\) occupies a portion of the sample space \(\Omega\) and the restricted space \(B\).
Like before, the probability \(P(A)\) is the proportion of the sample space \(\Omega\) taken up by \(A\) (shaded in blue on the left). However, if we know that \(B\) has happened, then we should restrict to outcomes in \(B\). The most natural definition of the conditional probability \(P(A|B)\) is then the proportion of the restricted space \(B\) taken up by \(A\) (specifically, the part of \(A\) that is in \(B\)).
Definition 5.1 formalizes this idea.
The frequentist interpretation of the conditional probability \(P(A|B)\) is straightforward: it is the proportion of times that \(A\) happens as the experiment is repeated over and over, ignoring the experiments where \(B\) did not happen. At the end of this chapter, we will discuss why Definition 5.1 is the right definition for capturing this interpretation.
Our first example uses Definition 5.1 to formally answer Secret Santa.
In some cases, conditional probabilities can be quite counterintuitive. To ensure that we correctly handle cases like our next example, it is imperative that we carefully apply Definition 5.1 when we want to compute conditional probabilities, and not just rely on intuition.
5.2 The Multiplication Rule
We can also combine the conditional probabilities to obtain the probability that multiple events happen simultaneously. To build some intuition as to why, we begin with a simple example. Say we draw the two cards from the top of a shuffled deck of \(52\) playing cards (see Figure 1.6). What is the probability that both cards are spades?
Because there are \(13\) spades in the deck, the first card should be a spade \(\frac{13}{52}\) of the time. Given that the first card is a spade, there are \(12\) spades remaining in a deck of \(51\) cards, so the second card will also be a spade \(\frac{12}{51}\) of the time. For both cards to be spades, both these events need to happen. This should happen \(12/51\) of \(13/52\) the time, or, in other words, \(\frac{13}{52} \cdot \frac{12}{51}\) of the time.
This is the idea behind the multiplication rule, which really is just a restatement of the definition of conditional probability (Definition 5.1).
The multiplication rule is useful when the conditional probability \(P(A \mid B)\) is easy to determine, but the joint probability \(P(A \cap B)\) is not. The next example provides such a scenario.
Example 5.3 (NBA Draft Lottery) The National Basketball Association (NBA) conducts a draft each year where teams select new talent. Since there are a few superstars each year, the first few draft picks are highly coveted. The order for the first three picks is determined by a lottery that is weighted so that the worst teams have the best chances of getting these picks.
Between 1990 and 1994, the lottery worked as follows: each of the 11 teams that did not make the playoffs the previous season would have a certain number of ping-pong balls with their names on them. The team with the worst record would have 11 balls, the team with the second-worst record would have 10 balls, and so on, down to the team with the best record, which would only have 1 ball—for a total of 66 balls. First, a ball was drawn to determine the team that gets the first pick. All of this team’s balls were removed, and another ball was drawn to determine the team that gets the second pick. All of this team’s balls were removed as well, and a third ball was drawn to determine the team that gets the third pick.
The 1992 NBA draft had one of the most talented pools ever. The 11 teams that were eligible for the top three picks, based on their win-loss record in the 1991-92 season, were:
- Houston Rockets (1 ball)
- Atlanta Hawks (2 balls)
- Philadelphia 76ers (3 balls)
- Charlotte Hornets (4 balls)
- Milwaukee Bucks (5 balls)
- Sacramento Kings (6 balls)
- Washington Bullets (7 balls)
- Denver Nuggets (8 balls)
- Dallas Mavericks (9 balls)
- Orlando Magic (10 balls)
- Minnesota Timberwolves (11 balls)

The teams that actually received the top 2 draft picks were the Orlando Magic (who selected Shaquille O’Neal) and Charlotte Hornets (who selected Alonzo Mourning). What was the probability of this? In other words, we want to calculate the joint probability \[ P(\{\text{Magic get 1st pick}\} \cap \{\text{Hornets get 2nd pick}\}). \]
It is not straightforward to describe a sample space of equally likely outcomes for the first two picks in this weighted lottery. (If you do not see why, try it!) The problem is that the number of balls remaining for the second pick depends on which team got the first pick.
However, it is easy to reason about the conditional probabilities. For example, \[ P(\text{Hornets get 2nd pick} \mid \text{Magic get 1st pick}) = \frac{4}{56} \] because if the Magic get the first pick, then there are \(66 - 10 = 56\) balls remaining, of which \(4\) belong to the Hornets.
Now, we can calculate the joint probability from the multiplication rule (Corollary 5.1). \[ \begin{align} P(\{\text{Magic get 1st pick}\} &\cap \{\text{Hornets get 2nd pick}\}) \\ &= P(\text{Magic get 1st pick}) P(\text{Hornets get 2nd pick} \mid \text{Magic get 1st pick}) \\ &= \frac{10}{66} \cdot \frac{4}{56} \\ &\approx 0.01. \end{align} \]
What is the probability that the top card of a shuffled deck of \(52\) playing cards is a spade? It is not hard to see that it is \(13/52\) by simply counting the spades. But what about the probability that the second card is a spade? The conditional probabilities are easy to calculate, by restricting the sample space to the \(51\) remaining cards after the first card is removed:
- \(P(\text{2nd card spade} \mid \text{1st card spade}) = \frac{12}{51}\)
- \(P(\text{2nd card spade} \mid \text{1st card not spade}) = \frac{13}{51}\)
But what about the unconditional probability that the second card is a spade? By symmetry, the answer must be \(13/52\). In a well-shuffled deck, there is nothing special about the 2nd card or the 35th card. If we have no other information, every card is equally likely to be any one of the 52 cards.
If you are not convinced by the symmetry argument, the next example, based on the multiplication rule, may help.
Example 5.4 (Selecting cards and probability trees) Suppose we draw two cards from the top of a shuffled deck of \(52\) playing cards. What is the probability that both cards are spades? What about the probability that the first card is not a spade but the second card is?
Let \(S_1\) be the event that the first card is a spade and \(S_2\) be the event that the second card is a spade. As we argued above,
- \(\displaystyle P(S_2 \mid S_1) = \frac{12}{51}\)
- \(\displaystyle P(S_2 \mid S_1^c) = \frac{13}{51}\)
However, it is not immediately obvious what \(P(S_1 \cap S_2)\) is.
One way to visualize these conditional probabilities and the multiplication rule is to draw a probability tree.
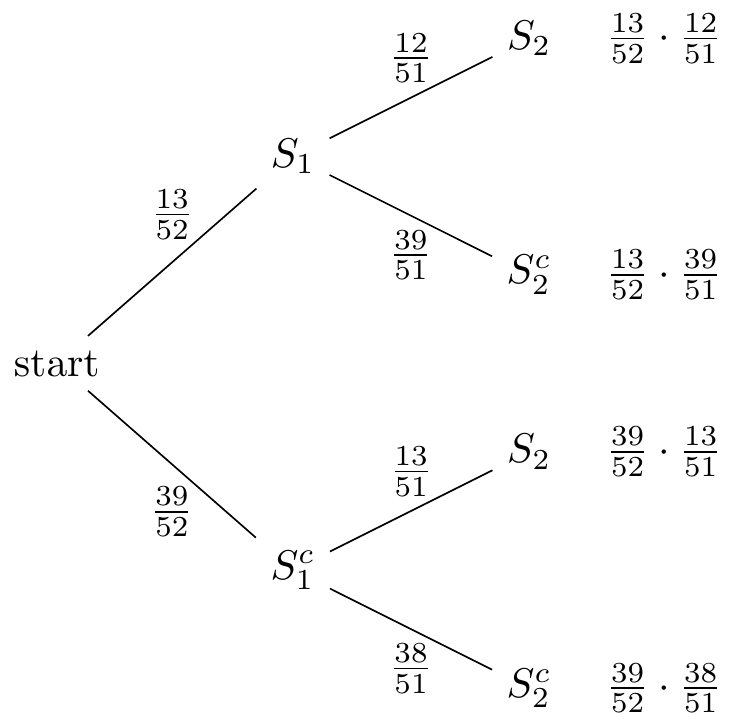
Each branch’s label shows the conditional probability of the event, given all the preceding events. For example:
- Path through \(S_1\) and \(S_2\): The path through \(S_1\) and \(S_2\) tells us that \(P(S_1) = \frac{13}{52}\) and \(P(S_2 \mid S_1) = \frac{12}{51}\).
- Path through \(S_1^c\) and \(S_2\): The path through \(S_1^c\) and \(S_2\) tells us that \(P(S_1^c) = \frac{39}{52}\) and \(P(S_2 \mid S_1^c) = \frac{13}{51}\).
At the end of each path, we write the product of all the probabilities along the path. The multiplication rule (Corollary 5.1) tells us that this final number is the joint probability of all of those events. For example:
- Drawing two spades: To find the probability of drawing two spades, we can follow the path through \(S_1\) and \(S_2\) to find that \(P(S_1 \cap S_2) = P(S_1)P(S_2 \mid S_1) = \frac{13}{52} \cdot \frac{12}{51}\) at the end.
- Drawing a non-spade and then a spade: Following the path through \(S_1^c\) and \(S_2\) we see that the probability that we draw a spade after drawing a non-spade is \(P(S_1^c \cap S_2) = P(S_1^c) P(S_2 \mid S^c_1) = \frac{39}{52} \cdot \frac{13}{51}\).
These are the two (mutually exclusive) ways that the second card can be a spade. Therefore, we can calculate the probability that the second card is a spade by adding these two probabilities together: \[ P(S_2) = \frac{13}{52} \cdot \frac{12}{51} + \frac{39}{52} \cdot \frac{13}{51} = \frac{13}{52}, \] which agrees with the symmetry argument we made earlier.
Probability trees quickly become unwieldy with a larger number of events. Still, they are a popular way of representing conditional probabilities and can be helpful for simple problems.
The multiplication rule realizes its full potential when generalized to more than two events. Before introducing this generalization, we first introduce some shorthand notation.
When working with many events \(A_1, \dots, A_n\), using \(P(A_1 \cap \dots \cap A_n)\) to denote the probability of all the events happening becomes cumbersome. Instead, we will adopt the shorthand notation
\[ P(A_1, \dots, A_n) \overset{\text{def}}{=}P(A_1 \cap \dots \cap A_n), \tag{5.5}\]
where commas inside a probability \(P(\dots)\) are read as “and”. For example,
- \(P(A_1, A_2, A_3)\) is the probability of “\(A_1 \text{ and } A_2 \text{ and } A_3\)” happening.
- \(P(A \mid B_1, \dots, B_n)\) is the probability of \(A\) happening, given that “\(B_1 \text{ and } B_2 \text{ and } \dots \text{ and } B_n\)” have all happened.
With this new notation, we can state the general multiplication rule.
In many settings, the multiplication rule enables us to easily compute the joint probability that many events happen simultaneously.
In our next example, we explore how the multiplication rule naturally appears in large language models, which are used by AI systems to generate text.
5.3 Conditional Probability Functions
A probability function \(P\) allocates a total probability of \(1\) among all outcomes in the sample space \(\Omega\). Conditioning on an event \(B\) reallocates this probability so that only outcomes in \(B\) are considered. In this new allocation, outcomes outside of \(B\) receive zero probability, while the probabilities of outcomes in \(B\) are rescaled proportionally so that the total probability is \(1\).
Proposition 5.1 formalizes this idea. In particular, it says that conditioning on an event is equivalent to defining a new probability function.
The most important consequence of Proposition 5.1 is that conditional probabilities automatically inherit all of the properties of probability, such as those presented in Chapter 4. We know immediately, for example, that all conditional probabilities also must be between zero and one (see Proposition 4.2). This provides an alternative way to analyze the Linda problem from Example 4.2.
We can also analyze a conditional version of the Linda problem, which is perhaps even more counterintuitive than the original problem.
Since \(\widetilde{P}\) is a probability function, we can further condition on another set \(C\) to obtain yet another probability function: \[ \widetilde{\widetilde P}(A) \overset{\text{def}}{=}\widetilde{P}(A \mid C). \] This corresponds to updating our probabilities twice: first in light of \(B\), then in light of \(C\). The next result shows that this is equivalent to updating our probabilities based on all the evidence at once, both \(B\) and \(C\).
Proposition 5.1 and Proposition 5.2 reassure us that conditional probabilities behave like probabilities in all the ways we expect. This makes sense because all probabilities are conditional probabilities in some sense, whether we explicitly specify the conditioning event or not. For example,
- In Example 1.6, we assumed that both parents were carriers of albinism and calculated the probability that the child is albino to be \(1/4\). Alternatively, we could have rephrased this as the conditional probability that the child is albino, given that the child’s parents are carriers.
- In the problem of points (Example 1.10), we assumed that the game was interrupted when the score was 5 to 3 and calculated the probability of Player A winning to be \(7/8\). Alternatively, we could have rephrased this as the conditional probability that Player A wins, given that the game is interrupted when the score was 5 to 3.
In other words, there are two ways to look at every problem: we can incorporate background information into the design of the sample space and experiment, or we can define a broader experiment with a larger sample space and condition on the background information. The two approaches should produce the same answers, which is why results like Proposition 5.1 and Proposition 5.2 must be true.
5.4 Interpreting Conditional Probabilities
Recall from Section 3.3 that there are two principal ways that probabilities can be interpreted: frequentism and subjectivism. In this section, we discuss how frequentists and subjectivists interpret conditional probabilities.
5.4.1 Frequentism
Recall that a frequentist interprets the probability \(P(A)\) as the long-run relative frequency of \(A\) when an experiment is repeated over and over. (See Equation 28.7.) For a frequentist, the corresponding interpretation for the conditional probability \(P(A \mid B)\) should be the long-run relative frequency of \(A\), but only among trials where we know that \(B\) has happened: \[ P(A \mid B) = \lim_{\text{\# trials} \rightarrow \infty} \frac{\text{\# trials where } A \text{ and } B \text{ happen} }{\text{\# trials where } B \text{ happens}}. \]
We can show that the frequentist interpretation of conditional probability implies Definition 5.1.
5.4.2 Subjectivism
Recall that a subjectivist interprets the probability \(P(A)\) as a subjective belief about whether \(A\) will happen or not. To make the concept of “belief” precise, we introduced the idea of betting. The subjectivist should be willing to offer or accept a bet priced at \(\$P(A)\) that pays \(\$1\) if \(A\) happens and nothing if it does not.
In the same vein, it makes sense that \(P(A | B)\) should represent their updated belief that \(A\) happens once they know that \(B\) has happened. That is, the subjectivist should be willing to offer or accept a bet priced at \(\$P(A | B)\), which only takes effect if \(B\) happens, that pays \(\$1\) if \(A\) happens and nothing if it does not.
The next example suggests why the subjective interpretation necessarily implies Definition 5.1. If a subjectivist did not accept the definition of conditional probability, then a Dutch book could be set up to arbitrage their incoherent beliefs.
Of course, Example 5.9 is not a proof that the subjective interpretation implies Definition 5.1. However, the same strategy can be used to construct a Dutch book against anyone whose beliefs violate the definition of conditional probability. You will fill in the details in Exercise 5.7.
5.5 Coda: The Gambler’s Fallacy
Returning to the roulette question posed at the beginning of the chapter, is a roulette wheel due for a black after \(9\) consecutive reds? We discussed how the relevant probability for a gambler who is considering entering the action after nine consecutive reds is the conditional probability \[ P(\text{10th spin is red} \mid \text{first 9 spins are red}), \] rather than the joint probability \[ P(\text{all 10 spins are red}). \]
We now have the tools to calculate this conditional probability: \[ \begin{align*} P(\text{10th spin is red} &\mid \text{first 9 spins are red}) \\ &= \frac{P(\{\text{first 9 spins are red}\} \cap \{ \text{10th spin is red}\})}{P(\text{first 9 spins are red}) } \\ &= \frac{P(\text{all 10 spins are red})}{P(\text{first 9 spins are red}) } \\ &= \frac{ 18^{10}/38^{10} }{18^{9}/38^{9} } \\ &= \frac{18}{38}. \end{align*} \]
Notice that this is the same as the probability that any spin is red, if we had no information about the previous spins. That is, \[ P(\text{10th spin is red} \mid \text{first 9 spins are red} ) = P(\text{10th spin is red}). \tag{5.8}\]
We see that there is no greater or lesser chance of winning after 9 consecutive reds. The erroneous idea that a roulette wheel could be “due” for a black is known as the gambler’s fallacy.
Equation 5.8 suggests a very special relationship between these two events. The information that one event happened does not change the probability that the other happens. When this is true, we say that the two events are independent. Chapter 6 explores this concept.
5.6 Exercises
Exercise 5.1 (Conditional Secret Santa with \(n\) friends) Extending Example 5.1, now consider a Secret Santa gift exchange with \(n\) friends. If we know that the first friend does not draw their own name, what is the probability that the second friend draws their own name? Give your answer in terms of \(n\).
Exercise 5.2 (NBA Draft) Continuing Example 5.3, the teams that won the first three picks in the 1992 NBA draft were the Orlando Magic, Charlotte Hornets, and the Minnesota Timberwolves.
- Calculate the probability that these three teams would win the first three picks, in this order.
- Calculate the probability that these three teams would win the first three picks, in any order. Do different orderings of the same three teams have the same probability?
Exercise 5.3 (Revisiting the conditional Linda problem)
- Using Proposition 5.1 and Proposition 5.2, provide a quick proof of the conditional multiplication rule: \[ P(A \cap B \mid C) = P(A \mid C) P(B \mid A \cap C) \] Doing this proof by expanding the definition of conditional probability is extremely cumbersome!
- Using the conditional multiplication rule, give another solution to the conditional Linda problem (Example 5.8) in the style of Example 5.7.
Exercise 5.4 (Designing a loaded die) Suppose that we want to reweight the faces of a six-sided die so that, when the rolled number is even, it is a six half of the time. If \(p_k\) is the probability of rolling \(k\) for \(k=1,\dots, 6\), what conditions on \((p_1, \dots, p_6)\) ensure that this condition is satisfied?
Exercise 5.5 (The winter girl problem) Suppose a family has two children. Find the probability that both children are girls, given that at least one of them is a girl who was born in winter. For this problem, assume that all possibilities for genders and seasons are equally likely.
Exercise 5.6 (Rolling two dice) Suppose we roll two fair dice.
- What is the probability of rolling a \(7\) given that the first die was a \(1\)?
- What is the probability of rolling a \(7\) given that at least one of the die was a \(1\)?
- What is the probability of rolling a \(11\) given that the first die was a \(4\)?
- What is the probability of rolling a \(11\) given that at least one of the die was a \(4\)?
Exercise 5.7 (Subjective interpretation implies Definition 5.1) Suppose that a subjectivist believes \[ P(B) P(A \mid B) \neq P(A \cap B). \] Show how their beliefs can be arbitraged by setting up a Dutch book.
(Hint: Consider the cases \(P(B) P(A \mid B) < P(A \cap B)\) and \(P(B) P(A \mid B) > P(A \cap B)\) separately. For the first case, you can use Example 5.9 as a template.)