8 Random Variables
$$
$$
\[ \def\X{\textcolor{orange}{X}} \def\Y{\textcolor{blue}{Y}} \def\RR{\textcolor{red}{R}} \def\S{\textcolor{gray}{S}} \]
In the preceding chapters, we calculated the probability of different events. We described each event as a set of outcomes. It is usually easier to assign a numeric value to each outcome and describe an event in terms of that numeric value. A random variable \(X(\omega)\), often abbreviated \(X\), is simply a function that assigns a numeric value to each possible outcome \(\omega\).
8.1 Discrete Random Variables
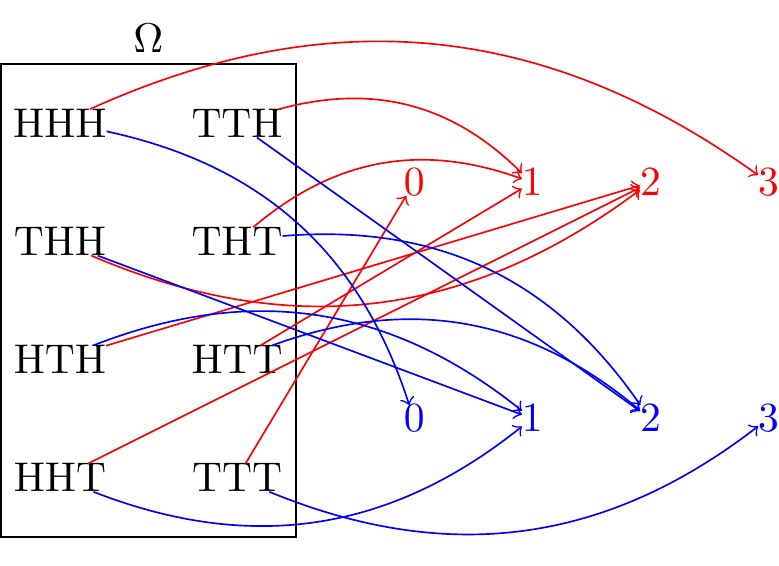
Example 8.1 (Numbers of heads and tails) Suppose a fair coin is tossed three times. The sample space \(\Omega\) is shown below. We can define different random variables on this sample space, depending on what quantity we are interested in. For example,
- \(\X = \text{the number of heads}\)
- \(\Y = \text{the number of tails}\)
are both random variables, and they are illustrated in Figure 8.1.
That is, the random variable \(\X\) is defined as: \[ \X(\omega) = \begin{cases} 0 & \omega \in \{ \texttt{TTT} \} \\ 1 & \omega \in \{ \texttt{HTT}, \texttt{THT}, \texttt{TTH} \} \\ 2 & \omega \in \{ \texttt{HHT}, \texttt{THH}, \texttt{HTH} \} \\ 3 & \omega \in \{ \texttt{HHH} \} \\ \end{cases}, \]
while the random variable \(\Y\) is defined as: \[ \Y(\omega) = \begin{cases} 0 & \omega \in \{ \texttt{HHH} \} \\ 1 & \omega \in \{ \texttt{HHT}, \texttt{THH}, \texttt{HTH} \} \\ 2 & \omega \in \{ \texttt{HTT}, \texttt{THT}, \texttt{TTH} \} \\ 3 & \omega \in \{ \texttt{TTT} \} \\ \end{cases}, \]
It is usually easier to express events of interest in terms of the random variables. For example, we can express the event \(\{ \text{more heads than tails} \}\) in a number of ways, such as:
- \(\{ \X \geq 2 \}\) (which is shorthand for \(\{ \omega: \X(\omega) \geq 2 \}\))
- \(\{ \Y \leq 1 \}\)
- \(\{ \X > \Y \}\)
So instead of writing \(P(\text{more heads than tails})\), we could instead write \(P(\X \geq 2)\) or \(P(\X > \Y)\).
In general, there are many random variables that could be defined on any sample space, and the “right” random variable is the one that helps us solve the problem.
The random variables we have described so far have had a limited set of possible values. For example, \(\X\) and \(\Y\) in Example 8.1 only assume the values \(\{ 0, 1, 2, 3 \}\), while \(S\) in Example 8.2 only assumes the values \(\{ -1, 35 \}\). These are all examples of discrete random variables. Later, in Chapter 18, we will encounter random variables that can assume any value in a range, such as \([0, 1]\), called continuous random variables.
Although we formally defined a random variable in Definition 8.1 as a function (on the sample space), it is usually easier to think of a random variable \(X\) as simply a variable (in the algebra sense) that happens to be representing a random quantity.
For example, since the number of heads and number of tails in Example 8.1 must add up to the number of tosses, \(3\), we can write \[ \X + \Y = 3, \] and we can use algebra to rearrange this equation as \[ \Y = 3 - \X. \] Although \(\X\) and \(\Y\) are technically functions, they really behave just like ordinary variables for most purposes.
8.2 Probability Mass Function
How do we describe a random variable, like \(\X\) from Example 8.1? We cannot know the value of \(\X\) for certain, but we can repeat the experiment many times and observe the different values of \(\X\) that occur.
The table above shows that \(\X = 1\) and \(\X = 2\) are more common than \(\X = 0\) and \(\X = 3\). The way that probabilities are distributed over these possible values is a property called the distribution of \(\X\).
One way to describe the distribution of a discrete random variable is its probability mass function (or PMF, for short). The PMF is a function that specifies the probability of each possible value of the random variable.
In the example below, we describe the distributions of \(\X\) and \(\Y\) from Example 8.1 by determining their PMFs.
Example 8.3 (Distributions of heads and tails) In Example 8.1, we defined two random variables:
- \(\X\), the number of heads in three tosses of a fair coin, and
- \(\Y\), the number of tails in three tosses of a fair coin.
Because each of the \(8\) outcomes in the sample space was equally likely, we can calculate the PMF by simply counting the number of outcomes corresponding to each value and dividing by \(8\).
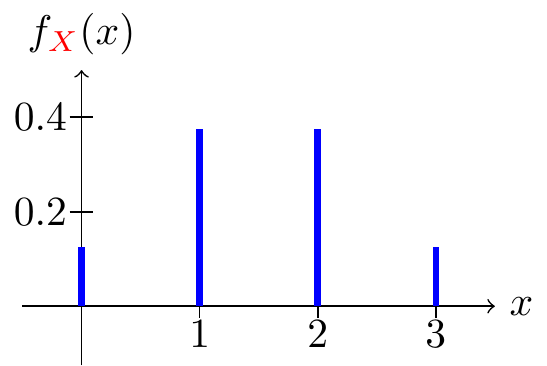
For example, we can calculate the PMF of \(\X\) as follows:
- \(f_{\X}(0) = P(\X = 0) = \frac{1}{8}\)
- \(f_{\X}(1) = P(\X = 1) = \frac{3}{8}\)
- \(f_{\X}(2) = P(\X = 2) = \frac{3}{8}\)
- \(f_{\X}(3) = P(\X = 3) = \frac{1}{8}\)
It is common to lay these probabilities out in a table.
| \(x\) | \(0\) | \(1\) | \(2\) | \(3\) |
|---|---|---|---|---|
| \(f_{\X}(x)\) | \(\frac{1}{8}\) | \(\frac{3}{8}\) | \(\frac{3}{8}\) | \(\frac{1}{8}\) |
The PMF of \(\X\) is graphed in Figure 8.2.
What about the PMF of \(\Y\)? Verify for yourself that it is the same!
| \(y\) | \(0\) | \(1\) | \(2\) | \(3\) |
|---|---|---|---|---|
| \(f_{\Y}(y)\) | \(\frac{1}{8}\) | \(\frac{3}{8}\) | \(\frac{3}{8}\) | \(\frac{1}{8}\) |
Even though \(\X\) and \(\Y\) have the same PMF, they are not the same random variable. In fact, \(\X = \Y\) would imply that the number of heads is always equal to the number of tails. But this is impossible when a coin is tossed 3 times! There is no outcome \(\omega\) for which \(\X(\omega) = \Y(\omega)\), so \[ P(\X = \Y) = 0. \]
Notice that the probabilities in any PMF always sum to \(1\). This is because events of the form \(\{ X = x_i \}\) are a partition of the sample space.
In order for a function \(f(x)\) to be a valid PMF, it must satisfy two properties:
- \(f(x) \geq 0\) for any \(x\), and
- There exist values \(x_1, x_2, \dots\) such that \(\displaystyle \sum_i f(x_i) = 1\).
In fact, any function \(f\) satisfying these two properties is the PMF of some random variable.
8.3 Cumulative Distribution Function
The PMF specifies the probability that a random variable is equal to a given value. Another way to describe the distribution of a random variable is to specify the probability that it is less than or equal to a given value. This function is called the cumulative distribution function (or CDF).
We can describe the random variable \(\X\) from Example 8.1 using its CDF.
Example 8.5 (CDF of the number of heads) Using the PMF of \(\X\) that we derived in Example 8.3, we can calculate the CDF of \(\X\) to be: \[ \begin{aligned} F_{\X}(x) &= \begin{cases} 0 & x < 0 \\ \frac{1}{8} & 0 \leq x < 1 \\ \frac{1}{8} + \frac{3}{8} & 1 \leq x < 2 \\ \frac{1}{8} + \frac{3}{8} + \frac{3}{8} & 2 \leq x < 3 \\ \frac{1}{8} + \frac{3}{8} + \frac{3}{8} + \frac{1}{8} & x \geq 3 \end{cases} \\ &= \begin{cases} 0 & x < 0 \\ \displaystyle 0.125 & 0 \leq x < 1 \\ \displaystyle 0.5 & 1 \leq x < 2 \\ \displaystyle 0.875 & 2 \leq x < 3 \\ 1 & x \geq 3 \end{cases}. \end{aligned} \tag{8.5}\]
This CDF is graphed in Figure 8.3.
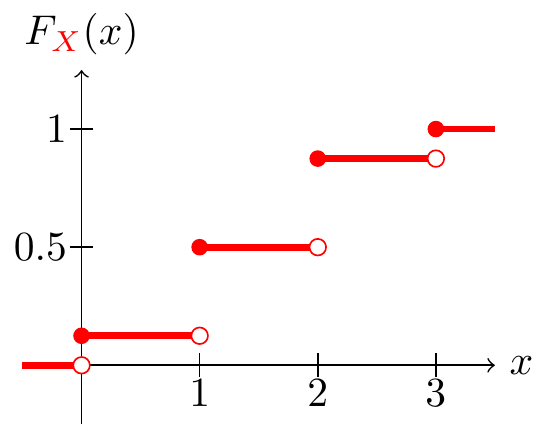
The CDF makes it easy to evaluate probabilities. For example, we can obtain the probability of getting more heads than tails, \(P(\X > 2)\), from Equation 8.5 with minimal calculation: \[ P(\X > 2) = 1 - P(\X \leq 1) = 1 - F_{\X}(1) = 1 - \frac{1}{2} = \frac{1}{2}. \]
Example 8.5 suggests several properties of a CDF:
- It is non-decreasing.
- As \(x\) approaches \(-\infty\), \(F_X(x)\) approaches \(0\).
- As \(x\) approaches \(\infty\), \(F_X(x)\) approaches \(1\).
- It is continuous from the right, and it has a limit from the left. (Mathematicians call such a function “càdlàg”, a French acronym for the phrase “continue à droite, limite à gauche.”)
Since the CDF is simply another way of describing the distribution of a random variable, we should be able to recover the PMF from the CDF (and vice versa). The next example shows that the “jumps” in the CDF correspond to the values of the PMF.
8.4 Bernoulli and Binomial Distributions
In this section, we introduce two families of distributions that arise so frequently in probability that they have names. Both can be described in terms of coin tossing.
Imagine that we have a coin that has a probability \(p\) of coming up heads. (Note that our imaginary coin is not necessarily fair.)
- The number of heads that come up in a single toss of this coin is a Bernoulli random variable.
- The number of heads that come up in \(n\) tosses of this coin is a binomial random variable.
If \(X\) is a Bernoulli random variable, then clearly \(X\) is either \(0\) or \(1\), and \(P(X = 1) = p\).
If \(X\) is a binomial random variable, the possible values of \(X\) are \(0, 1, \dots, n\). To determine the probability of each value, observe that the event \(\left\{ X = x \right\}\) means that there are \(x\) heads in the \(n\) tosses. For example, if \(n=4\) and \(x=2\), then \[ \{ X = 2 \} = \{ \texttt{HHTT}, \texttt{HTHT}, \texttt{HTTH}, \texttt{THHT}, \texttt{THTH}, \texttt{TTHH} \}. \]
Since all of these sequences have exactly \(x\) heads (and \(n-x\) tails), the probability of any one of them is \[ p^x (1 - p)^{n-x} \] (by Proposition 6.1), and the number of such sequences is \[ \binom{n}{x}, \] so by Proposition 4.4, \[ P(X = x) = \binom{n}{x} p^x (1-p)^{n-x}. \]
The binomial distribution reduces to the Bernoulli distribution when \(n=1\).
Even though we described the Bernoulli and binomial distributions in terms of coin tosses, these distributions can be applied to a wide variety of real-world situations. In order to apply them, we analogize the particular situation to coin tosses. The following examples illustrate this process.
The next example is another historical problem that engaged one of the greatest mathematicians of all time.
8.5 Geometric Distribution
In this section, we introduce another family of distributions that is so common that it has a name. It can also be described in terms of coin tossing.
Once again, suppose we have a coin that has a probability \(p\) of coming up heads. However, instead of tossing the coin a fixed number of times, we now toss the coin until heads comes up. The random variable \(N\) is the number of tosses.
Unlike the random variables we have considered so far, there is no upper bound to the possible values of \(N\) because tails could come up indefinitely. However, the idea is the same; to determine the distribution of \(N\), we need to calculate \[ f_N(n) = P(N = n) \] for \(n=1, 2, 3, \dots\).
The event \(\left\{ N = n \right\}\) means that the first \(n-1\) tosses were tails and the \(n\)th toss was heads. Because the tosses are independent, the probability of this is \[ P(N = n) = (1 - p)^{n-1} p. \]
This motivates the following definition.
To apply the geometric distribution to problems other than coin tossing, it helps to analogize the situation to coin tossing.
8.6 Exercises
When a question asks for the distribution of a random variable, any one of the following is sufficient:
- the PMF (either as a table or a formula)
- the CDF (either as a table or a formula)
- the name of the distribution (e.g., Bernoulli, binomial, geometric), along with the values of all parameters
Exercise 8.1 (Secret Santa random variable) Recall the Secret Santa example (Example 1.7). If \(X\) represents the number of friends who draw their own name,
- Determine the distribution of \(X\). Why is it not \(\textrm{Binomial}(n= 4, p= 1/4)\)?
- Verify that \(P(X > 0)\) agrees with the answer we obtained in Example 4.7.
Exercise 8.2 (One-and-one in basketball) In NCAA basketball, a team is “in the penalty” after 6 team fouls are committed in a half. If a player is fouled and the opposing team is in the penalty, the player is awarded a “one-and-one.”
The player is awarded a free throw (worth one point), and if they make it, they are awarded a second free throw.
If \(X\) is the number of points scored in a one-and-one, find the distribution of \(X\), assuming that the probability of making a free throw is \(0.75\), independent of any other free throw.
Exercise 8.3 (Field bet in craps) One of the most popular side bets in craps (Figure 1.8) is the field bet. Unlike the pass line bet, which is resolved over multiple rolls, the field bet is resolved in a single roll. The field bet wins if the next roll is a 2, 3, 4, 9, 10, 11, or 12. Typically, 2 and 12 pay double (2-to-1), while the other numbers pay 1-to-1. What is the PMF of the profit if you make a $1 field bet?
Exercise 8.4 (Floor function CDF) Let \(X\) be a random variable with CDF \[ F_X(x) = \begin{cases} 1 - 2^{\lfloor x \rfloor}, & x \geq 0 \\ 0, & \text{otherwise} \end{cases}. \] Note that \(\lfloor x \rfloor\) denotes the floor function, which is the largest integer \(\leq x\), so \(\lfloor 1.4 \rfloor = 1\), \(\lfloor -2.9 \rfloor = -3\), and \(\lfloor 3 \rfloor = 3\).
- Show that \(F_X\) is a valid CDF.
- Graph \(F_X(x)\).
- Calculate \(P(X > 3)\) and \(P(X = 3)\).
- What is the PMF \(f_X(x)\)?
Exercise 8.5 (Wine competition) In a wine competition, there are five wines from Napa and five wines from Bordeaux. Each judge is asked to rank the wines from 1 (best) to 10 (worst). Ties are not allowed. Suppose that a judge cannot tell the difference between the ten wines so that all \(10!\) possible rankings are equally likely. Let \(R\) be the rank of the best Napa wine on this judge’s scorecard. Calculate the PMF of \(R\), and check that it is a valid PMF.
Exercise 8.6 (Random variables in roulette) Xavier places a $5 bet on red on each of 3 spins of a roulette wheel.
- Let \(X\) be the number of bets he wins. Find the distribution of \(X\).
- Let \(W\) be his profit over the 3 spins (which may be negative). Find the distribution of \(W\).
Exercise 8.7 (Trying keys at random) A friend asked you to house-sit while she is on vacation. She gave you a keychain with \(n\) keys, but she forgot to tell you which key was the one to her apartment. You decide to try keys at random until you find the right one.
- Let \(X\) be the number of keys that you need to try if you discard keys that do not work. What are the PMF and CDF of \(X\)?
- Let \(Y\) be the number of keys that you need to try if you do not discard keys that do not work. What are the PMF and CDF of \(Y\)?
Exercise 8.8 (Properties of the geometric distribution)
- Show that Equation 8.8 is a valid PMF.
- Derive a simple formula (not involving sums) for the CDF \(F_X(x)\) of a geometric random variable. Note that your formula must be valid for all values of \(x\), not just integer values. (Hint: It might be helpful to express your formula in terms of the floor function \(\lfloor x \rfloor\), which is defined to be the largest integer \(\leq x\).)